| clarkb | johnsom: why is it querying resolving _http._tcp.mirror.regionone.fortnebula.opendev.org. SRV IN ? is that something apt does? | 00:00 |
|---|---|---|
| pabelanger | clarkb: is there no mirror info for vexxhost there? | 00:00 |
| pabelanger | also +2 | 00:00 |
| clarkb | pabelanger: only the mirrors that have been replaced with opendev.org ansible'd mirrors are there | 00:00 |
| pabelanger | kk | 00:00 |
| johnsom | Couldn't tell you. I thought that was odd too. | 00:00 |
| clarkb | also it is trying both cloudflare and google before it gives up | 00:01 |
| johnsom | Yeah, upping the ttl seems like we are just going to fail the download anyway if the IPv6 routing is down. | 00:01 |
| *** diablo_rojo has joined #openstack-infra | 00:02 | |
| diablo_rojo | rm_work, yeah they already went out | 00:02 |
| *** trident has joined #openstack-infra | 00:03 | |
| clarkb | I can resolve google.com via those two resolvers right now against the two nameservers that failed from the mirror host in that cloud | 00:04 |
| clarkb | johnsom: are we sure that the job itself isn't breaking the host's networking or unbound setup? | 00:04 |
| clarkb | johnsom: we have had jobs do that in the past | 00:04 |
| clarkb | I think either that is happenign or we have intermittent routing issues out of the cloud | 00:04 |
| johnsom | This happens over many different jobs/patches | 00:04 |
| clarkb | (because right now it seems to be fine) | 00:04 |
| johnsom | Looking at the unbound log it was fine at the start of the job too. | 00:05 |
| clarkb | johnsom: ya then the job runs and does stuff to the host :) | 00:05 |
| clarkb | according to that log it had successfully resolved records just 14 seconds prior | 00:05 |
| clarkb | with this being udp is it deciding the network is unreachable because the timeout is hit? | 00:07 |
| johnsom | Well it blew up devstack on the latest one. The patch doesn't change the devstack config (and frankly we haven't in a log time either). | 00:07 |
| *** rh-jelabarre has quit IRC | 00:07 | |
| clarkb | rtt to those two servers is 8ms currently if that timeout is in play | 00:07 |
| johnsom | Or there is no route, like the RA expired | 00:07 |
| clarkb | pabelanger: its direct via bgp | 00:10 |
| clarkb | er I was scrolled up and thougt that was familiar, sorry | 00:10 |
| rm_work | diablo_rojo: what was the title? I don't think I saw mine? | 00:11 |
| rm_work | and approx when? | 00:11 |
| clarkb | johnsom: fwiw the syslog entries for the time when unbound log starts logging thing shows updates to iptables and ebtables | 00:11 |
| *** armax has quit IRC | 00:11 | |
| johnsom | We dom | 00:12 |
| clarkb | johnsom: http://paste.openstack.org/show/770959/ | 00:12 |
| johnsom | We don't use either. We only use neutron SGs | 00:12 |
| clarkb | is it possible neutron is nuking it then? | 00:12 |
| *** stewie925 has quit IRC | 00:13 | |
| diablo_rojo | rm_work, I pinged Kendall Waters (she sent them) I'll let you know as soon as she replies. | 00:14 |
| rm_work | hmm k | 00:14 |
| rm_work | what's her nick? | 00:14 |
| clarkb | it is interesting that the console log shows only the apt stuff and not other tasks that could change iptables or ebtables or ovs | 00:14 |
| clarkb | maybe neutron background stuff as its turning on? /me checks neutron logs | 00:14 |
| johnsom | Maybe. There is ovs openflow stuff in there too, so probably neutron devstack stuff. | 00:14 |
| johnsom | If that was the case, why would the other providers and the py27 run of the same patch pass? | 00:16 |
| johnsom | And the two node version on py3, etc... | 00:16 |
| clarkb | it could be a race | 00:16 |
| clarkb | assuming iptables/ebtables/ovs is at fault somehow it they happen long enough after your apt stuff then apt will succeed and happily move on (and job amy not do anything elseexternal after that point?) | 00:17 |
| clarkb | I don't have enough evidence to say they are at fault but it is highly suspicious that we have network problems at around exactly the same time we muck with the network | 00:17 |
| clarkb | johnsom: Sep 04 22:04:29.894751 ubuntu-bionic-fortnebula-regionone-0010774925 neutron-dhcp-agent[13633]: DEBUG neutron.agent.linux.utils [-] Running command (rootwrap daemon): ['ip', 'netns', 'exec', 'qdhcp-89551ca5-1abb-484e-af0c-1a4f3c8e1d59', 'sysctl', '-w', 'net.ipv6.conf.default.accept_ra=0'] | 00:22 |
| clarkb | do network namespaces mask off sysctls? | 00:23 |
| clarkb | if not setting default there instead of the specific interface may be the problem | 00:23 |
| diablo_rojo | rm_work, sounds like they would have come from Jimmy or Ashlee and would have had "Open Infrastructure Summit Shanghai" in the subject | 00:25 |
| johnsom | They do mask some of them, yes. | 00:25 |
| clarkb | internet says the answer is it depends | 00:26 |
| clarkb | ya depends on the specific one | 00:26 |
| rm_work | diablo_rojo: hmm ok i'll search again | 00:26 |
| clarkb | https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt does not say if accept_ra is namespace specific or not | 00:27 |
| johnsom | Yeah, they are listed somewhere else. | 00:27 |
| clarkb | I feel like there is a good chance this is the problem | 00:27 |
| rm_work | diablo_rojo: yeah I don't see mine... who should I contact? | 00:29 |
| clarkb | neat k8s docs says its even trickier than that. Some sysctls can be set within a namespace but take effect globally | 00:30 |
| clarkb | so there are three types I think, those that are namespace specific, those that can be set in a namespace but take effect globally, and those that can only be set at the root namespace level | 00:31 |
| johnsom | I would be really surprised if the accept_ra isn't netns specific. It impacts the routing tables which are a key part of netns functionality. Still digging however. | 00:31 |
| clarkb | johnsom: yes, however it is specifically the default. one | 00:31 |
| clarkb | johnsom: I would not be surprised if default took affect more globally because its default | 00:32 |
| rm_work | diablo_rojo: ah, I found Kendall Waters' email. I'll shoot her a line. | 00:32 |
| diablo_rojo | rm_work, you found your code? | 00:32 |
| johnsom | I don't think so. | 00:32 |
| diablo_rojo | rm_work, sounds like it might not have come from her there are a few people that work on them but it should have been around the beginning of the month 8/5 or 8/6? | 00:33 |
| rm_work | diablo_rojo: no, I just mean I found her email *address*, and will email her directly instead of randomly trying to use you as an intermediary :D | 00:33 |
| *** bobh has joined #openstack-infra | 00:35 | |
| clarkb | docker default network setup doesn't let me change that sysctl | 00:35 |
| clarkb | probably have to try and reproduce using netns constructed like neutron | 00:36 |
| *** dychen has joined #openstack-infra | 00:38 | |
| johnsom | clarkb I just tried it. It is locked into the netns | 00:38 |
| *** zhurong has quit IRC | 00:38 | |
| *** gyee has quit IRC | 00:39 | |
| johnsom | Two different windows, but you can get the idea: http://paste.openstack.org/show/770960/ | 00:40 |
| johnsom | Oh, and a double paste on the first one. sigh | 00:40 |
| clarkb | johnsom: is line 79 after line 123 on the wall clock? | 00:42 |
| *** bobh has quit IRC | 00:42 | |
| johnsom | After 125 actually | 00:42 |
| johnsom | I wanted to make sure it actually stuck and didn't just silently ignore it | 00:43 |
| *** bobh has joined #openstack-infra | 00:45 | |
| clarkb | cool I can replicate that too | 00:46 |
| *** Goneri has quit IRC | 00:47 | |
| openstackgerrit | Clark Boylan proposed opendev/base-jobs master: We need to set the build shard var in post playbook too https://review.opendev.org/680239 | 00:48 |
| clarkb | infra-root ^ yay for testing. That was missed in my first change to base-test | 00:48 |
| openstackgerrit | Clark Boylan proposed zuul/zuul-jobs master: Add build shard log path docs to upload-logs(-swift) https://review.opendev.org/680240 | 00:50 |
| clarkb | johnsom: I'm betting someone like slaweq would be able to wade through these logs quicker to rule neutron stuff in or out | 00:52 |
| johnsom | clarkb FYI: https://ae2e20a98890c5458e58-1659b40e5c03e7f989419d6178d67ae8.ssl.cf5.rackcdn.com/679332/3/check/ironic-standalone-ipa-src/50285fa/controller/logs/devstacklog.txt.gz | 00:52 |
| johnsom | 2019-09-04 23:49:55.793 | 00:52 |
| johnsom | Other projects seem to be having the same issue | 00:52 |
| clarkb | johnsom: there are similar syslog'd network changes around the time that one fails dns too | 00:54 |
| clarkb | I think that is our next step. See if slaweq can help us understand what neutron is doing there to either rule it in or out | 00:54 |
| clarkb | and we can also have donnyd check for external routing problems | 00:54 |
| johnsom | Seems to only happen with the fortnebula instances | 00:55 |
| clarkb | fortnebula is our only ipv6 cloud right now (or did we turn on limestone again?) | 00:56 |
| clarkb | however if it is a timing thing then would be related to the cloud possibly | 00:56 |
| johnsom | Yeah, 100% of the hits in the last 24 hours were all fortnebula | 00:57 |
| clarkb | any idea why the worlddump doesn't seem to be working at the end of these devstack runs? it is supposed to capture things like ntwork state for us | 00:57 |
| clarkb | maybe we haven't listed that file as one to copy in the job? | 00:58 |
| johnsom | Though I guess I was only looking at the last 500 out of the 986 hits in the last 24 hours | 00:58 |
| johnsom | Hmm, I hadn't noticed that it disappeared | 00:59 |
| *** bobh has quit IRC | 01:00 | |
| *** markvoelker has joined #openstack-infra | 01:00 | |
| johnsom | None of the projects I have looked at have that worlddump file anymore. | 01:01 |
| donnyd | clarkb: how can i help | 01:01 |
| clarkb | so I think tahts the 3 next steps then. Fix worlddump, see if slaweq understands what neutron is doing and if that might play a part, and work with donnyd to check for ipv6 routing issues | 01:02 |
| clarkb | donnyd: we have some jobs in fortnebula that fail to resolve against 2606:4700:4700::1111 and 2001:4860:4860::8888 at times | 01:02 |
| clarkb | donnyd: https://79636ab1f0eaf6899dc0-686811860e75a35eabcecb5697905253.ssl.cf2.rackcdn.com/665029/30/check/octavia-v2-dsvm-scenario/51891fa/controller/logs/unbound_log.txt.gz shows this if you need examples | 01:03 |
| clarkb | the timestamp there translates to 2019-09-4T22:06:01Z | 01:03 |
| clarkb | johnsom: worlddump is exiting with return code 2? is that what the last line there means? | 01:04 |
| donnyd | why do i see no timestamps | 01:04 |
| donnyd | i haven't looked at the logs since the switch to swift | 01:05 |
| clarkb | donnyd: in that file [1567634761] is the timestamp which is an epoch time | 01:05 |
| *** markvoelker has quit IRC | 01:05 | |
| clarkb | it is due to how unbound logs | 01:05 |
| donnyd | [1567634761] unbound[792:0] debug: answer from the cache failed | 01:05 |
| clarkb | then you get [1567634761] unbound[792:0] notice: sendto failed: Network is unreachable and [1567634761] unbound[792:0] notice: remote address is ip6 2606:4700:4700::1111 port 53 (len 28) | 01:06 |
| donnyd | [1567634761] unbound[792:0] notice: sendto failed: Network is unreachable | 01:07 |
| clarkb | I've got to run to dinner now, but I expect fixing worlddump will help significantly | 01:07 |
| donnyd | ok | 01:07 |
| johnsom | clarkb I don't see any output from the worlddump.py line in the job I'm looking at now. So I don't know... | 01:07 |
| donnyd | PING 2606:4700:4700::1111(2606:4700:4700::1111) 56 data bytes | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=2 ttl=60 time=6.76 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=3 ttl=60 time=8.09 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=4 ttl=60 time=11.5 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=5 ttl=60 time=10.1 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=6 ttl=60 time=7.96 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=7 ttl=60 time=6.65 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=8 ttl=60 time=6.73 ms | 01:07 |
| donnyd | 64 bytes from 2606:4700:4700::1111: icmp_seq=9 ttl=60 time=7.23 ms | 01:07 |
| donnyd | i can turn on packet capture at the edge an find out what the dealio is | 01:08 |
| *** mattw4 has joined #openstack-infra | 01:08 | |
| clarkb | donnyd: ya I was able to resolve to the two resolvers from the mirror just fine | 01:09 |
| clarkb | and they both respond in ~8ms rtt so not a timeout issue unless that rtt skyrockets | 01:09 |
| *** slaweq has joined #openstack-infra | 01:11 | |
| clarkb | sean-k-mooney: fyi the sync-devstack-data role is what is supposed to copy the CA stuff around but it runs after devstack runs on the subnodes | 01:12 |
| clarkb | sean-k-mooney: I noticed this when debugging worlddump really quickly | 01:12 |
| clarkb | I can write or test a change tonight but you might just try move that role before the sub node devstack runs | 01:12 |
| clarkb | *I can't | 01:12 |
| clarkb | ianw frickler ^ fyi you may be interested in those two things (worlddump not working and sync-devstack-data not running before the subnodes) | 01:13 |
| clarkb | and now really dinner | 01:13 |
| *** slaweq has quit IRC | 01:15 | |
| donnyd | johnsom: so resolution works the entire way through the job, but then fails at the end | 01:20 |
| johnsom | It seems to fail part way through | 01:21 |
| donnyd | where | 01:21 |
| *** zhurong has joined #openstack-infra | 01:21 | |
| *** mattw4 has quit IRC | 01:21 | |
| *** calbers has quit IRC | 01:22 | |
| donnyd | the resolve failure is at the end of the job, but I am curious if it from switching between v6 and v4... | 01:22 |
| clarkb | our job setup will switch the ipv6 clouds to ipv6 at the brginning of the job | 01:23 |
| clarkb | before that the default is ipv4 | 01:23 |
| johnsom | donnyd 2019-09-04 23:49:55.794760 in this ironic job: https://ae2e20a98890c5458e58-1659b40e5c03e7f989419d6178d67ae8.ssl.cf5.rackcdn.com/679332/3/check/ironic-standalone-ipa-src/50285fa/job-output.txt | 01:23 |
| donnyd | 2019-09-04 23:49:55.161 | ++ /opt/stack/ironic/devstack/lib/ironic:create_bridge_and_vms:1868 : sudo ip route replace 10.1.0.0/20 via 172.24.5.219 | 01:24 |
| johnsom | 2019-09-04 22:06:01.847407 in our Octavia job https://79636ab1f0eaf6899dc0-686811860e75a35eabcecb5697905253.ssl.cf2.rackcdn.com/665029/30/check/octavia-v2-dsvm-scenario/51891fa/job-output.txt | 01:24 |
| *** yamamoto has joined #openstack-infra | 01:24 | |
| johnsom | For the octavia job, it's still setting up devstack, it hasn't started our tests yet | 01:25 |
| donnyd | Well that job is doing the same as the other | 01:27 |
| donnyd | failing at the end | 01:27 |
| donnyd | 2019-09-04 21:57:20.422065 | controller | Get:1 http://mirror.regionone.fortnebula.opendev.org/ubuntu bionic-updates/universe amd64 qemu-user amd64 1:2.11+dfsg-1ubuntu7.17 [7,354 kB] | 01:27 |
| donnyd | works at the beginning of the job, but not at the end | 01:27 |
| donnyd | i wonder if any of the other projects are having this issue | 01:27 |
| johnsom | Well, the logs end because the devstack start failed.... | 01:27 |
| donnyd | yes, the logs end | 01:28 |
| johnsom | Those two were the ones I saw in a quick search of the last 24s. The job needs to attempt to pull packages in, i.e. a devstack bindep for this error to report. | 01:29 |
| johnsom | 24hrs, sorry | 01:30 |
| clarkb | ya and in those two neutron is making network changes around when it starts to fail | 01:30 |
| clarkb | hence my suspicion that may be related | 01:30 |
| johnsom | They appear time clustered, but the sample size is a bit small given we don't always have jobs running that need to call out | 01:31 |
| johnsom | https://usercontent.irccloud-cdn.com/file/CtLQgDRl/image.png | 01:32 |
| donnyd | I am also happy to get you some debugging instances if that will help | 01:32 |
| donnyd | How long has it been doing this? | 01:35 |
| johnsom | a month or two from what I remember. The gates were not logging the unbound messages before, so we were not sure why the DNS lookups were failing | 01:36 |
| *** calbers has joined #openstack-infra | 01:37 | |
| donnyd | 2019-09-04 22:05:04.371936 | controller | + lib/neutron_plugins/services/l3:_neutron_configure_router_v6:423 : sudo ip -6 addr replace 2001:db8::2/64 dev br-ex | 01:37 |
| donnyd | 2019-09-04 22:05:04.382939 | controller | + lib/neutron_plugins/services/l3:_neutron_configure_router_v6:424 : local replace_range=fd4d:5343:322e::/56 | 01:37 |
| donnyd | 2019-09-04 22:05:04.385798 | controller | + lib/neutron_plugins/services/l3:_neutron_configure_router_v6:425 : [[ -z 163f0224-ac00-44b8-931b-0ec01a216a4c ]] | 01:37 |
| donnyd | 2019-09-04 22:05:04.388395 | controller | + lib/neutron_plugins/services/l3:_neutron_configure_router_v6:428 : sudo ip -6 route replace fd4d:5343:322e::/56 via 2001:db8::1 dev br-ex | 01:37 |
| donnyd | what are these configuring? | 01:37 |
| johnsom | That I don't know. That is neutron setup steps in devstack. | 01:39 |
| donnyd | do you have a local.conf for this job? | 01:39 |
| *** bobh has joined #openstack-infra | 01:39 | |
| donnyd | Or a way to run it on a test box? | 01:39 |
| donnyd | I think that is going to be the fastest way to the bottom | 01:40 |
| johnsom | Here is one from an octavia job: https://ae2e20a98890c5458e58-1659b40e5c03e7f989419d6178d67ae8.ssl.cf5.rackcdn.com/679332/3/check/ironic-standalone-ipa-src/50285fa/controller/logs/local_conf.txt.gz | 01:41 |
| johnsom | I don't think this is easy to reproduce, but I also haven't looked to see if we have had successes at fortnebula. Let me look at the other jobs | 01:42 |
| *** bobh has quit IRC | 01:44 | |
| donnyd | http://logstash.openstack.org/#/dashboard/file/logstash.json?query=node_provider:%5C%22fortnebula-regionone%5C%22%20AND%20message:%5C%22Temporary%20failure%20resolving%5C%22&from=3h | 01:48 |
| donnyd | So it looks to me like ironic-standalone-ipa-src and octavia-v2-dsvm-scenario have issues | 01:50 |
| donnyd | but i don't see any other jobs with that issue | 01:50 |
| donnyd | i should say octavia-* | 01:50 |
| johnsom | Right, most jobs don't pull in packages later in the stack process | 01:50 |
| johnsom | Ok, yes, there have been successful runs at fortnebula: https://821d285ecb2320351bef-f1e24edd0ae51a8de312c1bf83189630.ssl.cf1.rackcdn.com/672477/7/check/octavia-v2-dsvm-scenario-amphora-v2/5f2878d/job-output.txt | 01:52 |
| donnyd | do these jobs only test against ubuntu? | 01:52 |
| johnsom | No, there are centos as well | 01:52 |
| johnsom | At least for octavia, I can't talk to ironic | 01:52 |
| *** bobh has joined #openstack-infra | 01:53 | |
| donnyd | its looks to me like the failures are 100% ubuntu | 01:53 |
| *** bobh has quit IRC | 01:54 | |
| johnsom | Yeah, so it looks like the IPv6 DNS lookups are intermittent I see a number that were successful over the last two days. | 01:54 |
| johnsom | Our centos job has only landed on fortnebula three times in the last week, so, small sample size. | 01:58 |
| donnyd | yea that is a small sample size | 01:59 |
| donnyd | Hrm... well I surely need to keep an eye on it | 01:59 |
| *** markvoelker has joined #openstack-infra | 02:01 | |
| johnsom | Yeah, maybe fire up a script that does a IPv6 lookup of mirror.regionone.fortnebula.opendev.org on DNS server 2001:4860:4860::8888 every 5-10 minutes. See if you get some failures. | 02:01 |
| johnsom | I also need to step away now. Thanks for your time looking into it. | 02:02 |
| donnyd | NP | 02:02 |
| donnyd | lmk how else i can be helpful | 02:02 |
| *** markvoelker has quit IRC | 02:05 | |
| *** bobh has joined #openstack-infra | 02:09 | |
| *** apetrich has quit IRC | 02:10 | |
| *** jklare has quit IRC | 02:12 | |
| *** jklare has joined #openstack-infra | 02:20 | |
| *** bhavikdbavishi has joined #openstack-infra | 02:40 | |
| *** bhavikdbavishi1 has joined #openstack-infra | 02:43 | |
| *** bobh has quit IRC | 02:43 | |
| *** bhavikdbavishi has quit IRC | 02:44 | |
| *** bhavikdbavishi1 is now known as bhavikdbavishi | 02:44 | |
| *** bobh has joined #openstack-infra | 02:46 | |
| *** nicolasbock has quit IRC | 02:49 | |
| *** jamesmcarthur has quit IRC | 02:49 | |
| *** jamesmcarthur has joined #openstack-infra | 02:50 | |
| *** bobh has quit IRC | 02:50 | |
| *** jamesmcarthur has quit IRC | 02:55 | |
| *** xinranwang has joined #openstack-infra | 02:56 | |
| *** slaweq has joined #openstack-infra | 03:11 | |
| *** slaweq has quit IRC | 03:15 | |
| *** jamesmcarthur has joined #openstack-infra | 03:20 | |
| *** markvoelker has joined #openstack-infra | 03:31 | |
| *** jklare has quit IRC | 03:35 | |
| *** jklare has joined #openstack-infra | 03:35 | |
| *** markvoelker has quit IRC | 03:41 | |
| *** calbers has quit IRC | 03:44 | |
| *** calbers has joined #openstack-infra | 03:47 | |
| *** ricolin has joined #openstack-infra | 03:49 | |
| *** exsdev has joined #openstack-infra | 04:17 | |
| *** ramishra has joined #openstack-infra | 04:20 | |
| *** jtomasek has joined #openstack-infra | 04:29 | |
| *** markvoelker has joined #openstack-infra | 04:30 | |
| *** markvoelker has quit IRC | 04:35 | |
| *** jtomasek has quit IRC | 04:40 | |
| *** jamesmcarthur has quit IRC | 04:47 | |
| *** larainema has joined #openstack-infra | 04:48 | |
| *** raukadah is now known as chandankumar | 04:49 | |
| *** kjackal has joined #openstack-infra | 04:51 | |
| *** jtomasek has joined #openstack-infra | 04:51 | |
| *** udesale has joined #openstack-infra | 05:02 | |
| *** yamamoto has quit IRC | 05:09 | |
| *** slaweq has joined #openstack-infra | 05:11 | |
| *** adriant has quit IRC | 05:11 | |
| *** adriant has joined #openstack-infra | 05:12 | |
| *** slaweq has quit IRC | 05:15 | |
| *** jamesmcarthur has joined #openstack-infra | 05:17 | |
| *** jamesmcarthur has quit IRC | 05:22 | |
| *** dychen has quit IRC | 05:28 | |
| *** markvoelker has joined #openstack-infra | 05:30 | |
| *** ccamacho has quit IRC | 05:32 | |
| *** dchen has quit IRC | 05:33 | |
| *** markvoelker has quit IRC | 05:35 | |
| *** psachin has joined #openstack-infra | 05:37 | |
| openstackgerrit | Andreas Jaeger proposed zuul/zuul-jobs master: Add build shard log path docs to upload-logs(-swift) https://review.opendev.org/680240 | 05:40 |
| *** georgk has quit IRC | 05:40 | |
| *** fdegir has quit IRC | 05:40 | |
| *** georgk has joined #openstack-infra | 05:40 | |
| *** fdegir has joined #openstack-infra | 05:40 | |
| AJaeger | config-core, please put https://review.opendev.org/679850 and https://review.opendev.org/679856 on your review queue | 05:51 |
| AJaeger | config-core, and also https://review.opendev.org/679743 and https://review.opendev.org/676430 and https://review.opendev.org/#/c/678573/ | 05:52 |
| AJaeger | infra-root, we have a Zuul error on https://zuul.opendev.org/t/openstack/config-errors: "philpep/testinfra - undefined (undefined)" | 05:56 |
| *** kjackal has quit IRC | 06:03 | |
| *** dchen has joined #openstack-infra | 06:04 | |
| *** snecker has joined #openstack-infra | 06:04 | |
| openstackgerrit | OpenStack Proposal Bot proposed openstack/project-config master: Normalize projects.yaml https://review.opendev.org/680298 | 06:16 |
| *** jamesmcarthur has joined #openstack-infra | 06:19 | |
| *** jamesmcarthur has quit IRC | 06:23 | |
| *** kopecmartin|off is now known as kopecmartion | 06:23 | |
| *** slaweq has joined #openstack-infra | 06:24 | |
| *** kopecmartion is now known as kopecmartin | 06:24 | |
| *** ccamacho has joined #openstack-infra | 06:27 | |
| *** slaweq has quit IRC | 06:28 | |
| *** snecker has quit IRC | 06:29 | |
| *** yamamoto has joined #openstack-infra | 06:29 | |
| *** psachin has quit IRC | 06:31 | |
| *** zhurong has quit IRC | 06:37 | |
| *** yamamoto has quit IRC | 06:42 | |
| *** yamamoto has joined #openstack-infra | 06:43 | |
| openstackgerrit | Merged openstack/project-config master: Remove broken notification for starlingx https://review.opendev.org/679850 | 06:46 |
| openstackgerrit | Merged openstack/project-config master: Finish retiring networking-generic-switch-tempest-plugin https://review.opendev.org/679743 | 06:48 |
| *** openstackgerrit has quit IRC | 06:51 | |
| *** slaweq has joined #openstack-infra | 06:52 | |
| *** udesale has quit IRC | 06:56 | |
| *** diga has joined #openstack-infra | 06:58 | |
| *** janki has joined #openstack-infra | 06:58 | |
| *** jamesmcarthur has joined #openstack-infra | 06:59 | |
| *** yamamoto has quit IRC | 07:00 | |
| *** snecker has joined #openstack-infra | 07:03 | |
| *** yamamoto has joined #openstack-infra | 07:03 | |
| *** markvoelker has joined #openstack-infra | 07:06 | |
| *** jamesmcarthur has quit IRC | 07:06 | |
| *** markvoelker has quit IRC | 07:10 | |
| *** kjackal has joined #openstack-infra | 07:15 | |
| *** tesseract has joined #openstack-infra | 07:15 | |
| *** trident has quit IRC | 07:21 | |
| *** tosky has joined #openstack-infra | 07:23 | |
| *** pgaxatte has joined #openstack-infra | 07:29 | |
| *** trident has joined #openstack-infra | 07:29 | |
| *** rcernin has quit IRC | 07:33 | |
| *** jpena|off is now known as jpena | 07:33 | |
| *** trident has quit IRC | 07:34 | |
| *** openstackgerrit has joined #openstack-infra | 07:38 | |
| openstackgerrit | Merged openstack/project-config master: Normalize projects.yaml https://review.opendev.org/680298 | 07:38 |
| *** trident has joined #openstack-infra | 07:43 | |
| *** sshnaidm|afk is now known as sshnaidm|ruck | 07:43 | |
| *** snecker has quit IRC | 07:46 | |
| *** zhurong has joined #openstack-infra | 07:53 | |
| *** dchen has quit IRC | 07:56 | |
| *** dchen has joined #openstack-infra | 07:57 | |
| *** dchen has quit IRC | 08:00 | |
| openstackgerrit | Fabien Boucher proposed zuul/zuul master: Pagure - handle initial comment change event https://review.opendev.org/680310 | 08:01 |
| *** jamesmcarthur has joined #openstack-infra | 08:02 | |
| *** tkajinam has quit IRC | 08:05 | |
| *** jamesmcarthur has quit IRC | 08:07 | |
| *** ralonsoh has joined #openstack-infra | 08:20 | |
| *** derekh has joined #openstack-infra | 08:31 | |
| *** dtantsur|afk is now known as dtantsur | 08:38 | |
| *** e0ne has joined #openstack-infra | 08:41 | |
| *** markvoelker has joined #openstack-infra | 08:45 | |
| *** markvoelker has quit IRC | 08:50 | |
| amotoki | hi, when I open https://zuul.opendev.org/t/openstack/build/91b360daabc8453dba13129f78aca17b, I see an error "Payment Required Access was denied for financial reasons." when trying to open "Artifacts links. | 08:50 |
| amotoki | is it a known issue? | 08:50 |
| frickler | amotoki: yes, see notice from yesterday. OVH is working on fixing this, you'll need to recheck to get new logs if you need to see them earlier | 08:56 |
| frickler | clarkb: worlddump seems to be working fine, the errors that are logged are expected. we just fail to collect its output :(. I didn't find the reference to sync-devstack-data not working on subnodes, does someone have logs for that | 08:57 |
| amotoki | frickler: thanks. I missed that. | 08:57 |
| *** noama has quit IRC | 08:58 | |
| frickler | AJaeger: infra-root: that looks more like an issue with the github api, the repo itself seems to be in place for me: "404 Client Error: Not Found for url: https://api.github.com/installations/1549290/access_tokens" | 09:00 |
| *** trident has quit IRC | 09:01 | |
| *** jamesmcarthur has joined #openstack-infra | 09:04 | |
| *** jamesmcarthur has quit IRC | 09:08 | |
| *** trident has joined #openstack-infra | 09:09 | |
| *** bexelbie has quit IRC | 09:11 | |
| *** kjackal has quit IRC | 09:16 | |
| *** kjackal has joined #openstack-infra | 09:18 | |
| *** pkopec has joined #openstack-infra | 09:18 | |
| *** ociuhandu has joined #openstack-infra | 09:23 | |
| ianw | yeah i'd note that only recently we enabled the zuul ci side of things there | 09:24 |
| ianw | we've got the system-config job running on it, but it has always failed; i need to look into it. should be back tomorrow | 09:24 |
| ianw | (it being testinfa) | 09:24 |
| *** gfidente has joined #openstack-infra | 09:29 | |
| *** yamamoto has quit IRC | 09:35 | |
| *** xenos76 has joined #openstack-infra | 09:36 | |
| frickler | ianw: when did "only recently" happen and where? it seems we have patches in the check queue waiting for nodes since 14h, could that be related? e.g. https://review.opendev.org/680158 | 09:38 |
| *** yamamoto has joined #openstack-infra | 09:40 | |
| *** jamesmcarthur has joined #openstack-infra | 09:40 | |
| frickler | seems we have a high rate of "deleting nodes" in grafana since 21:00 which would match that timeframe | 09:40 |
| frickler | seeing quite a lot of these in nodepool-launcher.log on nl01: 2019-09-05 09:41:24,333 INFO nodepool.driver.NodeRequestHandler[nl01-21267-PoolWorker.rax-iad-main]: Not enough quota remaining to satisfy request 300-0005089060 | 09:42 |
| frickler | also ram quota errors like http://paste.openstack.org/show/771269/ | 09:44 |
| *** jamesmcarthur has quit IRC | 09:45 | |
| frickler | hmm, this one looks like rackspace doesn't even let us use all of the quota. or can this happen with multiple lauch requests in parallel? Quota exceeded for instances: Requested 1, but already used 220 of 222 i | 09:46 |
| frickler | nstances | 09:46 |
| *** bhavikdbavishi has quit IRC | 09:52 | |
| frickler | infra-root: unless someone has a better idea, I'd suggest to try and gently lower the quota we use on rackspace in an attempt to reduce the ongoing churn | 10:07 |
| sean-k-mooney | clarkb: thanks for looking into the ca issue. for now ill stick with truning off the tls_proxy until after m3 but assiming moveing sync-devstack-data resolves the issue then we can obviously turn it back on. | 10:09 |
| *** udesale has joined #openstack-infra | 10:20 | |
| *** udesale has quit IRC | 10:28 | |
| *** udesale has joined #openstack-infra | 10:29 | |
| ianw | frickler: i'd have to look back, but a few weeks. but i think maybe we might need to restart zuul to pick up the changes as it wasn't authorized to access the testinfra github project when it was launched. i *think* there may be some bits that don't actively reload themselves | 10:29 |
| ianw | sorry no idea on the quota bits | 10:29 |
| *** bexelbie has joined #openstack-infra | 10:39 | |
| *** ramishra has quit IRC | 10:39 | |
| *** nicolasbock has joined #openstack-infra | 10:41 | |
| *** jamesmcarthur has joined #openstack-infra | 10:41 | |
| *** yamamoto has quit IRC | 10:42 | |
| *** jamesmcarthur has quit IRC | 10:46 | |
| *** markvoelker has joined #openstack-infra | 10:46 | |
| *** kjackal has quit IRC | 10:47 | |
| *** iurygregory has joined #openstack-infra | 10:48 | |
| *** gfidente has quit IRC | 10:52 | |
| *** markvoelker has quit IRC | 10:52 | |
| AJaeger | config-core, please review https://review.opendev.org/680240 https://review.opendev.org/680239 https://review.opendev.org/676430 , https://review.opendev.org/678573 and https://review.opendev.org/679652 | 10:56 |
| *** ramishra has joined #openstack-infra | 11:06 | |
| *** jamesmcarthur has joined #openstack-infra | 11:18 | |
| *** kjackal has joined #openstack-infra | 11:19 | |
| *** jpena is now known as jpena|lunch | 11:21 | |
| *** jamesmcarthur has quit IRC | 11:23 | |
| *** ociuhandu has quit IRC | 11:23 | |
| *** beagles has joined #openstack-infra | 11:24 | |
| *** lpetrut has joined #openstack-infra | 11:27 | |
| *** bexelbie has quit IRC | 11:30 | |
| *** rosmaita has left #openstack-infra | 11:35 | |
| *** bexelbie has joined #openstack-infra | 11:36 | |
| *** bexelbie has quit IRC | 11:36 | |
| *** yamamoto has joined #openstack-infra | 11:36 | |
| *** ociuhandu has joined #openstack-infra | 11:39 | |
| *** ociuhandu has quit IRC | 11:40 | |
| *** ociuhandu has joined #openstack-infra | 11:41 | |
| *** ociuhandu has quit IRC | 11:41 | |
| *** ociuhandu has joined #openstack-infra | 11:42 | |
| *** ociuhandu has quit IRC | 11:43 | |
| *** ociuhandu has joined #openstack-infra | 11:44 | |
| *** gfidente has joined #openstack-infra | 11:45 | |
| *** ociuhandu has quit IRC | 11:50 | |
| AJaeger | infra-root, I agree, something is wrong with out nodes - we have a requirements change waiting since 14 hours for a node for example... | 11:53 |
| *** yamamoto has quit IRC | 11:54 | |
| Shrews | AJaeger: That may not necessarily be something wrong with nodepool. If zuul gets hung up on something, it probably already has the nodes it has requested, it just isn't progressing and using them. That's what we've seen most in these cases. Do you have a node request number for the change in question? | 11:57 |
| AJaeger | Shrews: see backscroll and comments by frickler - I have no further information and I'm not an admin. | 11:58 |
| Shrews | frickler: ^^^ | 11:58 |
| AJaeger | Shrews: example change https://review.opendev.org/680107 in http://zuul.opendev.org/t/openstack/status | 11:59 |
| AJaeger | "Not enough quota remaining to satisfy request 300-0005089060" - is that what you need, Shrews ? | 11:59 |
| AJaeger | That is from backscroll | 12:00 |
| *** yamamoto has joined #openstack-infra | 12:00 | |
| *** jamesmcarthur has joined #openstack-infra | 12:00 | |
| AJaeger | Shrews: and http://paste.openstack.org/show/771269/ has details | 12:00 |
| *** roman_g has joined #openstack-infra | 12:01 | |
| Shrews | 2019-09-05 09:46:34,399 DEBUG nodepool.driver.NodeRequestHandler[nl01-21267-PoolWorker.rax-iad-main]: Fulfilled node request 300-0005089060 | 12:01 |
| Shrews | that request was satisfied hours ago. if the change for that is not doing anything still, that points to a zuul problem | 12:01 |
| *** markvoelker has joined #openstack-infra | 12:02 | |
| AJaeger | I don't know - frickler, do you? ^ | 12:02 |
| Shrews | and if zuul is holding requested nodes longer than it needs to, it just puts excessive pressure on the entire system (causing the quota issues mentioned) | 12:03 |
| frickler | Shrews: it's well possible that zuul would need a restart, possibly related to what ianw mentioned, but I'm not going to touch it myself | 12:04 |
| Shrews | AJaeger: frickler: looks like the node used in that request was deleted not long after the request was fulfilled | 12:04 |
| *** virendra-sharma has joined #openstack-infra | 12:04 | |
| *** bhavikdbavishi has joined #openstack-infra | 12:10 | |
| *** virendra-sharma has quit IRC | 12:13 | |
| *** rh-jelabarre has joined #openstack-infra | 12:14 | |
| Shrews | AJaeger: frickler: from what I can tell, nodepool never even received that request until 2019-09-05 09:41:14, so it processed it rather quickly. | 12:15 |
| *** yamamoto has quit IRC | 12:16 | |
| frickler | we do seem to be slowly progressing, not completely stuck. maybe indeed all is well except that we are running at or above capacity | 12:18 |
| AJaeger | we have 8 hold nodes - do we still need those? | 12:19 |
| Shrews | oh, that node request does not even belong to the referenced change | 12:19 |
| frickler | corvus: pabelanger: mnaser: ianw: mordred: do you still need your held nodes? all of them > 10 days old | 12:20 |
| pabelanger | frickler: nope, that can be deleted | 12:21 |
| AJaeger | we have 50 nodes deleting in limestone: http://grafana.openstack.org/d/WFOSH5Siz/nodepool-limestone?orgId=1 | 12:22 |
| AJaeger | and 201 in ovh: http://grafana.openstack.org/d/BhcSH5Iiz/nodepool-ovh?orgId=1 | 12:22 |
| AJaeger | but 0 building. frickler, that might be the problem with the deleting you noticed ^ | 12:22 |
| haleyb | clarkb: do you still have question on accept_ra sysctls in the dhcp namespace? I can't tell from scrollback. Don't think that should be an issue, but i'd be happy to look into it | 12:22 |
| pabelanger | AJaeger: looks like outages | 12:23 |
| AJaeger | so, that looks like the billing issue with ovh - | 12:23 |
| AJaeger | I'm aware of a swift billing issue, didn't know it affected nodes as well | 12:23 |
| AJaeger | is nodepool getting confused with trying to delete 200 ovh nodes and not succeeding? | 12:24 |
| *** yamamoto has joined #openstack-infra | 12:26 | |
| *** ociuhandu has joined #openstack-infra | 12:27 | |
| logan- | limestone has the host aggregate disabled cloud-side as a precautionary measure while we're ironing out an outage with an upstream carrier.. we've disabled the host aggregate this way in the past and it didn't have adverse affects with nodepool, but I wonder if maybe there's a scale issue with us + the ovh nodes? | 12:28 |
| *** ociuhandu has quit IRC | 12:32 | |
| *** eharney has joined #openstack-infra | 12:41 | |
| frickler | indeed this is what nl04 sees from ovh-gra1: keystoneauth1.exceptions.http.Unauthorized: The account is disabled for user: 6b66bafa4e214d5ab62928c8d7372b2b. (HTTP 401) (Request-ID: req-3e92a20a-058e-4ff6-a1f0-745f341bb8fa) | 12:42 |
| frickler | going to disable that zone | 12:42 |
| *** yamamoto has quit IRC | 12:43 | |
| openstackgerrit | Jens Harbott (frickler) proposed openstack/project-config master: Disable OVH in nodepool due to accounting issues https://review.opendev.org/680397 | 12:45 |
| frickler | infra-root: ^^ we might need to force-merge if checks take too long | 12:45 |
| *** rh-jelabarre has quit IRC | 12:46 | |
| AJaeger | frickler: so, is that really a problem for nodepool? Doesn't it handle that error properly? | 12:47 |
| AJaeger | frickler: changes ahead of it in the queue got nodes assigned in 2-5 minutes, so shouldn't take too long | 12:48 |
| pabelanger | I'd be surpried if nodepool is having an issue because of it | 12:49 |
| pabelanger | but, could be possible | 12:49 |
| amorin | hey clarkb | 12:49 |
| pabelanger | in the past, provider outages haven't been an impact to nodepool | 12:49 |
| amorin | hey all | 12:50 |
| amorin | is the tenant on ovh still down? | 12:51 |
| amorin | the team is supposed to enabled it back this morning (french time) | 12:51 |
| pabelanger | amorin: yes, we are just disabling it now | 12:51 |
| pabelanger | might still be related to accounting? | 12:51 |
| frickler | amorin: at least it was 10 minutes ago | 12:51 |
| amorin | pabelanger, frickler spawn still not possible? | 12:52 |
| frickler | amorin: keystone say account 6b66bafa4e214d5ab62928c8d7372b2b is disabled | 12:52 |
| pabelanger | amorin: correct: http://grafana.openstack.org/dashboard/db/nodepool-ovh | 12:52 |
| AJaeger | amorin, and swift is still asking for payment | 12:53 |
| amorin | checking | 12:53 |
| amorin | I have a guy on phone call checking ATM | 12:53 |
| AJaeger | thanks, amorin . Much appreciated! | 12:54 |
| *** Goneri has joined #openstack-infra | 12:55 | |
| amorin | frickler: what is 6b66bafa4e214d5ab62928c8d7372b2b ? | 12:55 |
| amorin | its not a tenant? | 12:55 |
| amorin | what we have is: dcaab5e32b234d56b626f72581e3644c | 12:56 |
| frickler | amorin: user id probably | 12:56 |
| amorin | ok | 12:56 |
| amorin | yes user is disabled | 12:56 |
| amorin | we are checking | 12:56 |
| *** bhavikdbavishi has quit IRC | 12:56 | |
| *** yamamoto has joined #openstack-infra | 12:58 | |
| AJaeger | frickler, pabelanger , I think we should not merge the ovh disable change while amorin is on it- do you agree and want to WIP it? | 12:58 |
| frickler | AJaeger: ack, done | 12:59 |
| *** jpena|lunch is now known as jpena | 13:01 | |
| amorin | frickler: AJaeger pabelanger users are ok now | 13:04 |
| amorin | could you check? | 13:04 |
| *** ramishra has quit IRC | 13:04 | |
| *** ramishra has joined #openstack-infra | 13:04 | |
| *** jamesmcarthur has quit IRC | 13:04 | |
| *** bhavikdbavishi has joined #openstack-infra | 13:04 | |
| *** jchhatbar has joined #openstack-infra | 13:05 | |
| *** jcoufal has joined #openstack-infra | 13:06 | |
| *** janki has quit IRC | 13:06 | |
| *** mriedem has joined #openstack-infra | 13:07 | |
| frickler | amorin: I don't see any change yet | 13:07 |
| amorin | ok, I still have some tasks ongoing, wait a minute | 13:07 |
| *** jchhatba_ has joined #openstack-infra | 13:08 | |
| amorin | frickler: could you test again? | 13:09 |
| frickler | amorin: yep, looks better now | 13:09 |
| amorin | yay | 13:10 |
| *** pcaruana has quit IRC | 13:10 | |
| *** jchhatbar has quit IRC | 13:11 | |
| frickler | amorin: so at least I can manually list servers, our nodepool service seems to have a bit of a hickup. thanks anyway for fixing this | 13:11 |
| frickler | amorin: the swift issue still seems to persist, though, I'm assuming that will take longer to handle? | 13:12 |
| amorin | ah, it's supposed to fix also | 13:13 |
| amorin | checking | 13:13 |
| rledisez | frickler: there is few minutes of cache so now that the tenant is enabled, it should be ok in few minutes | 13:13 |
| amorin | thanks rledisez | 13:13 |
| rledisez | frickler: is it the same tenant ? | 13:13 |
| rledisez | just to double check | 13:13 |
| amorin | rledisez: the user is on the same tenant | 13:13 |
| frickler | rledisez: amorin: indeed, after another reload this seems to work now, too. thx alot | 13:14 |
| rledisez | frickler: perfect. let us know if you hit other issues | 13:14 |
| AJaeger | yeah, swift works - thanks amorin and rledisez ! | 13:14 |
| amorin | sorry for that | 13:15 |
| AJaeger | frickler: nodepool is not yet using ovh according to http://grafana.openstack.org/d/BhcSH5Iiz/nodepool-ovh?orgId=1 ? | 13:15 |
| *** eernst has quit IRC | 13:16 | |
| frickler | AJaeger: nl04 seems to be recovering from suddenly getting useful responses, I'd tend to wait a bit and see what happens | 13:16 |
| AJaeger | ok | 13:17 |
| AJaeger | frickler: want to abandon https://review.opendev.org/#/c/680397/ now? | 13:18 |
| *** ociuhandu has joined #openstack-infra | 13:18 | |
| frickler | AJaeger: done | 13:21 |
| *** bhavikdbavishi has quit IRC | 13:28 | |
| AJaeger | frickler, pabelanger: Did either of you remove pabelanger's hold nodes? | 13:29 |
| pabelanger | I have not, I can do in a bit | 13:30 |
| pabelanger | or somebody else can, if they'd like | 13:30 |
| mnaser | i dont need my holds | 13:30 |
| mnaser | sorry i didnt update | 13:31 |
| *** rosmaita has joined #openstack-infra | 13:32 | |
| corvus | frickler: i deleted my nodes, thanks for the reminder | 13:33 |
| corvus | frickler, AJaeger: i'd like to restart the executors, but that's going to create a bit of nodepool churn; do you think we're stable enough for that now, or should we defer that for a few hours? | 13:35 |
| fungi | i am around today, modulo several hours of meetings starting shortly, but am declaring bankruptcy on the last 36 hours of irc scrollback in here | 13:35 |
| corvus | fungi: glad to see you! | 13:36 |
| fungi | thanks! glad to be high and dry here in the mountains for the next several days | 13:36 |
| *** ginopc has quit IRC | 13:37 | |
| smcginnis | Good to hear you are safe and dry. | 13:38 |
| *** pcaruana has joined #openstack-infra | 13:39 | |
| AJaeger | corvus: we just enabled ovh again - but they are not picking up nodes yet according to grafana. Let's wait until ovh is healthy | 13:39 |
| AJaeger | corvus: so, my advise: Let's figure out ovh - and the nrestart. We might need to restart nl04 as well... | 13:41 |
| *** smarcet has joined #openstack-infra | 13:42 | |
| corvus | AJaeger: ack; i'll take a look at the nl04 logs | 13:42 |
| corvus | AJaeger, frickler, Shrews: since frickler said that new commands work, but nothing is currently working on nl04, i wonder if there's something cached in the keystone session that's blocking us... how about i go ahead and restart nl04 and we can maybe learn whether that's the case? | 13:44 |
| *** jchhatba_ has quit IRC | 13:44 | |
| corvus | actually... new theory: | 13:45 |
| corvus | i'm only seeing logs about deleting servers | 13:45 |
| corvus | frickler: you said you were able to list servers -- do we still have a lot of servers in the account? | 13:46 |
| AJaeger | http://grafana.openstack.org/d/BhcSH5Iiz/nodepool-ovh?orgId=1&refresh=1m is confusing, it shows deleting at 0 | 13:46 |
| AJaeger | but if you look further down at "Test Node History", it still shows them as deleting | 13:47 |
| corvus | i get a grafana error for that dashboard | 13:47 |
| *** bnemec has quit IRC | 13:48 | |
| AJaeger | does http://grafana.openstack.org/d/BhcSH5Iiz/nodepool-ovh work? | 13:48 |
| corvus | (or maybe a graphite error) | 13:48 |
| AJaeger | works for me... | 13:48 |
| *** bnemec has joined #openstack-infra | 13:48 | |
| corvus | nope, i get http://paste.openstack.org/ | 13:48 |
| corvus | grr | 13:48 |
| corvus | http://paste.openstack.org/show/771445/ | 13:48 |
| AJaeger | ;/ | 13:49 |
| * AJaeger has to step out now | 13:49 | |
| corvus | i get that for every nodepool dashboard | 13:49 |
| corvus | oh. privacy badger :) | 13:51 |
| *** rh-jelabarre has joined #openstack-infra | 13:51 | |
| corvus | one really has to get used to debugging the internet if using pb | 13:52 |
| corvus | i've triggered the debug handler, and the objgraph part of that is taking a long time | 13:56 |
| corvus | probably because we do in fact have a memory leak, and it has to page everything in | 13:56 |
| Shrews | corvus: for zuul or the launcher? | 13:57 |
| corvus | nl04 | 13:57 |
| corvus | or... | 13:57 |
| corvus | is it possible the debug handler crashed? | 13:58 |
| fungi | corvus: yep, a while back i discovered i needed to okay grafana.openstack.org embedding images from graphite.openstack.org (again, i think it's the .openstack.org cookies causing it for me) | 13:58 |
| corvus | cause the program seems to be running again now, with no iowait/swapping. but sigusr2 doesn't work anymore, and i still never saw anything after 2019-09-05 13:53:09,563 DEBUG nodepool.stack_dump: Most common types: | 13:58 |
| fungi | er, graphite.openDEV.org | 13:59 |
| fungi | so maybe not the domain cookie | 13:59 |
| *** smarcet has quit IRC | 13:59 | |
| corvus | Shrews: these are the stack traces i got from the pool workers: http://paste.openstack.org/show/771446/ http://paste.openstack.org/show/771447/ | 14:00 |
| corvus | i can't tell if they're stuck there in a deadlock or not (since i can't run the handler twice) | 14:00 |
| corvus | i think we've got all we're going to from nl04 and we should restart it now | 14:00 |
| corvus | (some NodeDeleter threads also have similar tracebacks) | 14:01 |
| corvus | Shrews: any objection to a restart, or should i go for it? | 14:01 |
| Shrews | corvus: go for it. i suspect changing something with the user auth caused some wonkiness within keystoneauth | 14:02 |
| Shrews | but those stack traces seem... off | 14:03 |
| corvus | yeah, i'm sure at least one dependency has changed from under us | 14:03 |
| corvus | maybe even nodepool itself | 14:04 |
| *** ociuhandu has quit IRC | 14:04 | |
| corvus | okay, it's doing stuff now. running into a lot of quota issues, but hopefully that will even out | 14:04 |
| corvus | (as the old, improperly accounted-for nodes are deleted) | 14:05 |
| *** lpetrut has quit IRC | 14:05 | |
| corvus | and there are nodes in-use now | 14:05 |
| corvus | so looks like things are okay again | 14:06 |
| *** pcaruana has quit IRC | 14:12 | |
| *** yamamoto has quit IRC | 14:16 | |
| *** yamamoto has joined #openstack-infra | 14:16 | |
| johnsom | Any pointers on how I can debug "RETRY_LIMIT" job failures? There appear to be no logs: https://zuul.opendev.org/t/openstack/build/c612b1c80c0c4dd49d39706d2a6cc4a5 | 14:19 |
| *** ociuhandu has joined #openstack-infra | 14:20 | |
| *** smarcet has joined #openstack-infra | 14:20 | |
| *** yamamoto has quit IRC | 14:21 | |
| *** jamesmcarthur has joined #openstack-infra | 14:23 | |
| corvus | johnsom: you might be able to recheck the change and then follow the streaming console log when it starts running | 14:25 |
| *** yamamoto has joined #openstack-infra | 14:25 | |
| *** ociuhandu has quit IRC | 14:25 | |
| corvus | when the release queue clears i'm going to restart the executors | 14:25 |
| *** smarcet has quit IRC | 14:29 | |
| *** lpetrut has joined #openstack-infra | 14:29 | |
| corvus | #status log restarted nl04 to deal with apparently stuck keystone session after ovh auth fixed | 14:32 |
| openstackstatus | corvus: finished logging | 14:32 |
| corvus | #status log restarted zuul executors with commit cfe6a7b985125325605ef192b2de5fe1986ef569 | 14:32 |
| openstackstatus | corvus: finished logging | 14:32 |
| *** armstrong has joined #openstack-infra | 14:35 | |
| *** smarcet has joined #openstack-infra | 14:36 | |
| *** yamamoto has quit IRC | 14:37 | |
| *** yamamoto has joined #openstack-infra | 14:39 | |
| frickler | corvus: sorry, was afk for a bit. when I checked there were only a few servers listed, 3 in one region and about 10 in the other | 14:42 |
| frickler | corvus: there are also two ancient puppet apply processes on nl04, shall we just kill those? | 14:42 |
| corvus | frickler: great, i think that matches the observed behavior | 14:43 |
| corvus | frickler: ++ | 14:43 |
| *** jamesmcarthur has quit IRC | 14:43 | |
| frickler | corvus: finally, did you look at the config error? ianw mentioned that this might also need a restart to resolve http://zuul.openstack.org/config-errors | 14:43 |
| corvus | frickler: has our app been installed in that repo? | 14:44 |
| corvus | (or was it installed after we reconfigured to add the repo?) | 14:45 |
| frickler | corvus: I have no idea. the repo seems to have been in the config for some months if I checked correctly | 14:45 |
| *** mattw4 has joined #openstack-infra | 14:46 | |
| *** udesale has quit IRC | 14:46 | |
| *** lpetrut has quit IRC | 14:47 | |
| frickler | https://review.opendev.org/657461 | 14:47 |
| *** udesale has joined #openstack-infra | 14:47 | |
| *** gyee has joined #openstack-infra | 14:50 | |
| corvus | frickler: let's check with ianw | 14:51 |
| corvus | frickler: but if it's a transient error, then we should be able to fix it with a full reconfiguration | 14:51 |
| *** smarcet has quit IRC | 14:53 | |
| *** armax has joined #openstack-infra | 14:56 | |
| *** piotrowskim has quit IRC | 14:58 | |
| *** cmurphy|afk is now known as cmurphy | 14:58 | |
| donnyd | can someone take a look at the nodepool logs for FN. I am having an issue with the new labels I created for NUMA | 15:00 |
| donnyd | It would be super helpful to know what nodepool is throwing as an error | 15:01 |
| *** jamesmcarthur has joined #openstack-infra | 15:02 | |
| *** e0ne has quit IRC | 15:05 | |
| Shrews | donnyd: all i'm seeing are quota issues | 15:07 |
| donnyd | Ok, i will just pull the quota entirely | 15:07 |
| Shrews | donnyd: what are the new labels? | 15:08 |
| donnyd | https://github.com/openstack/project-config/blob/master/nodepool/nl02.openstack.org.yaml#L348-L357 | 15:08 |
| donnyd | multi-numa-ubuntu-bionic-expanded | 15:08 |
| donnyd | multi-numa-ubuntu-bionic | 15:08 |
| donnyd | those are the ones i am concerned with | 15:09 |
| Shrews | donnyd: this is the most recent reference to one of those: http://paste.openstack.org/show/771452/ | 15:09 |
| donnyd | thanks Shrews | 15:10 |
| donnyd | that is what i needed | 15:10 |
| clarkb | corvus: fungi can I get review on https://review.opendev.org/#/c/680239/ that is next step for swift container sharding | 15:11 |
| clarkb | if tests look good for ^ I'll push up a change for base-minimal and base | 15:11 |
| clarkb | also is there a change to add ovh back to those jobs? | 15:11 |
| corvus | clarkb: no change i'm aware of | 15:12 |
| donnyd | also I am not sure how up to date the dashboard is... but its says its been deleting 29 instances for a while... | 15:14 |
| donnyd | they have been gone since about 37 seconds after the request for delete was placed | 15:14 |
| openstackgerrit | Clark Boylan proposed opendev/base-jobs master: Revert "Stop storing logs in OVH" https://review.opendev.org/680446 | 15:14 |
| clarkb | corvus: ^ for OVH | 15:14 |
| *** tosky has quit IRC | 15:15 | |
| *** smarcet has joined #openstack-infra | 15:16 | |
| *** mattw4 has quit IRC | 15:17 | |
| *** jamesmcarthur has quit IRC | 15:21 | |
| *** jamesmcarthur has joined #openstack-infra | 15:22 | |
| *** ccamacho has quit IRC | 15:26 | |
| openstackgerrit | Clark Boylan proposed zuul/zuul-jobs master: Add build shard log path docs to upload-logs(-swift) https://review.opendev.org/680240 | 15:27 |
| *** jamesmcarthur has quit IRC | 15:27 | |
| clarkb | infra-root https://review.opendev.org/#/c/680236/ bumps mirror TTLs up to an hour which was something we noticed with johnsom's dns debugging last night | 15:29 |
| clarkb | slaweq: if you have time today it would be great if you could look at these jobs logs from johnsom to double check that neutron isn't breaking host ipv6 networking which results in broken dns | 15:29 |
| clarkb | slaweq: at around the same time that dns stops working syslog records a bunch of changes by neutron in iptables, ebtables, ovs, and sysctl | 15:30 |
| slaweq | clarkb: sorry, I'm on meeting now and will go offline just after it | 15:31 |
| slaweq | clarkb: I can look at it tomorrow morning | 15:31 |
| johnsom | Repaste: An ironic job example: https://ae2e20a98890c5458e58-1659b40e5c03e7f989419d6178d67ae8.ssl.cf5.rackcdn.com/679332/3/check/ironic-standalone-ipa-src/50285fa/job-output.txt | 15:31 |
| slaweq | is it this link https://github.com/openstack/neutron/commit/f21c7e2851bc99b424bdc5322dcd0e3dee7ee5a3 ? | 15:31 |
| *** jamesmcarthur has joined #openstack-infra | 15:31 | |
| *** ociuhandu has joined #openstack-infra | 15:31 | |
| johnsom | repaste: an octavia log example: https://79636ab1f0eaf6899dc0-686811860e75a35eabcecb5697905253.ssl.cf2.rackcdn.com/665029/30/check/octavia-v2-dsvm-scenario/51891fa/job-output.txt | 15:32 |
| clarkb | slaweq: the one that johnsom just pasted. Job ends up failing beacuse dns stops working | 15:32 |
| clarkb | slaweq: cross checking timestamps in the unbound log and in syslog I see dns stops working about when neutron is making networking changes | 15:32 |
| clarkb | there is a lotof moving parts there so I ended up getting lost but figured someone that knows neutron would be able to get through it more easily | 15:32 |
| johnsom | clarkb Any advice on this? https://zuul.opendev.org/t/openstack/build/c612b1c80c0c4dd49d39706d2a6cc4a5 | 15:33 |
| fungi | clarkb: 680236 needs a serial increase | 15:33 |
| slaweq | clarkb: I will look into it later today or tomorrow morning | 15:33 |
| clarkb | fungi: oh right | 15:33 |
| clarkb | slaweq: thank you | 15:33 |
| openstackgerrit | Clark Boylan proposed opendev/zone-opendev.org master: Increase mirror ttls to an hour https://review.opendev.org/680236 | 15:34 |
| clarkb | fungi: ^ done and thank you | 15:34 |
| clarkb | johnsom: did you see the suggestion of watching the job? typically that means it is failing badly enough that we lose network connectivity and fail to copy logs | 15:35 |
| clarkb | johnsom: but if you watch the console log that is live streamed so you'll get the data before networking goes away | 15:35 |
| johnsom | clarkb I did, I'm just not sure how to guess which job is going to have the RETRY_LIMIT, it seems to move around. | 15:36 |
| clarkb | is it specific to that change? | 15:36 |
| johnsom | no | 15:36 |
| *** ociuhandu has quit IRC | 15:36 | |
| johnsom | I will try to catch one, just hoped there was a better way | 15:37 |
| clarkb | Not really. We could try to set up holds but if host networking is getting nuked we won't be able to login and debug with a hold | 15:37 |
| clarkb | we can check the executor logs to see if there are any crumbs of info there but other than that catching one live is probalby our best bet | 15:38 |
| clarkb | johnsom: could it be nested virt causing crashes? | 15:38 |
| johnsom | clarkb We disabled that over a year ago | 15:38 |
| fungi | rules that out then i guess | 15:38 |
| johnsom | clarkb Due to the nodepool image kernel issue at ovh | 15:38 |
| johnsom | This just started around the 3rd | 15:39 |
| *** smarcet has left #openstack-infra | 15:39 | |
| clarkb | johnsom: http://paste.openstack.org/show/771454/ as suspected it appeas to be crashing due to connectivity issues | 15:42 |
| clarkb | during tempest | 15:42 |
| clarkb | if you catch a live one you'll probably be able to narrow it down to the test that ran prior | 15:43 |
| clarkb | maybe look for changes in your tempest tests the last few days | 15:44 |
| johnsom | I did, we haven't changed them since the 16th | 15:45 |
| clarkb | other things it could be (but usually this is more widespread) zuul OOMing and losing its ZK Locks on nodes | 15:45 |
| * clarkb checks cacti | 15:46 | |
| clarkb | http://cacti.openstack.org/cacti/graph.php?action=view&local_graph_id=64792&rra_id=all seems ok | 15:46 |
| *** yamamoto has quit IRC | 15:53 | |
| *** yamamoto has joined #openstack-infra | 15:54 | |
| *** yamamoto has quit IRC | 15:54 | |
| *** yamamoto has joined #openstack-infra | 15:57 | |
| *** yamamoto has quit IRC | 15:57 | |
| *** yamamoto has joined #openstack-infra | 15:57 | |
| *** sshnaidm|ruck is now known as sshnaidm|afk | 16:00 | |
| clarkb | should I be concerned that the opendev base jobs updates seem to just be sitting in zuul http://zuul.opendev.org/t/opendev/status ? | 16:00 |
| *** altlogbot_3 has quit IRC | 16:01 | |
| *** yamamoto has quit IRC | 16:02 | |
| *** altlogbot_3 has joined #openstack-infra | 16:02 | |
| *** smarcet has joined #openstack-infra | 16:03 | |
| *** irclogbot_3 has quit IRC | 16:03 | |
| *** irclogbot_2 has joined #openstack-infra | 16:04 | |
| johnsom | I hate to say it, but if you look at the main zuul board, jobs are backed up 18+ hours and other projects are seeing the retries as well. | 16:05 |
| haleyb | johnsom: so does the job failure happen at the same place every time? looks like it's when it's going to setup diskimage-builder from the link above | 16:05 |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: Remove support for ansible 2.5 https://review.opendev.org/650431 | 16:05 |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: Switch ansible_default to 2.8 https://review.opendev.org/676695 | 16:05 |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: WIP: Support Ansible 2.9 https://review.opendev.org/674854 | 16:05 |
| clarkb | johnsom: ya I'm wodnering if this is executor restart fallout | 16:05 |
| johnsom | The top job for cinder has more than an handful doing "2. attempt" | 16:05 |
| clarkb | they aren't running | 16:05 |
| clarkb | johnsom: ya because executors were stopped | 16:06 |
| clarkb | corvus: ^ fyi I don't think they came back up again | 16:06 |
| corvus | clarkb: oh, well that makes me sad | 16:06 |
| *** irclogbot_2 has quit IRC | 16:07 | |
| johnsom | haleyb Hi there. The common "timing" is both jobs install additional packages later in the devstack setup. | 16:07 |
| *** irclogbot_2 has joined #openstack-infra | 16:07 | |
| clarkb | johnsom: haleyb ya one theory I had was most jobs don't haev a problem because dns gets broken after they are done doing external work | 16:08 |
| haleyb | i just don't see where any of the neutron agents are actively doing anything that would cause it | 16:08 |
| clarkb | johnsom: haleyb but if projects like octavia and ironic do extra after neutron comes up and sets up its networking that could explain why they see it | 16:08 |
| johnsom | haleyb When they attempt to go out and get those, the DNS queries fail. This only occurs when the DNS is using IPv6. | 16:08 |
| clarkb | haleyb: check syslog | 16:08 |
| slaweq | clarkb: I don't see anything in neutron that could break this IPv6 | 16:08 |
| slaweq | clarkb: but I have to leave now, sorry | 16:09 |
| clarkb | haleyb: there is a bunch of ovs, iptables, ebtables and such right around teh same time period (starting at the same second and continuing after) | 16:09 |
| clarkb | corvus: anything I can do to help? | 16:09 |
| corvus | clarkb: i restarted them. was just a systemd timeout | 16:09 |
| clarkb | ah | 16:09 |
| clarkb | johnsom: haleyb I do still think fixing worlddump will help quite a bit | 16:11 |
| clarkb | since that should give us the networking state after things break | 16:11 |
| clarkb | and we can work backward from there if necessary (or it will say everything is fine) | 16:12 |
| haleyb | clarkb: the iptables, etc calls are after the failure from what i see - 2019-09-04 22:06:01.847407 is dns failure, Sep 04 22:06:05 is first "ip netns exec..." call, so not sure it's the culprit yet | 16:14 |
| clarkb | haleyb: in the agent log that starts earlier (I don't know why there is a mismatch in logs timestamps. maybe one is at start and the other is at completion?) | 16:15 |
| *** xinranwang has quit IRC | 16:15 | |
| *** mattw4 has joined #openstack-infra | 16:15 | |
| clarkb | but ya we are running worlddump and it does nothing, that should be fixed as it exists specifically to debug these problems | 16:16 |
| haleyb | i've seen dns failure locally before, typically when "stack.sh" moves IPs to the OVS bridge, sometimes networkmanager trips over itself, but i just work around that by hardcoding dns servers in resolv.conf | 16:16 |
| clarkb | we hardcode them in the unbound config then hardcode resolv.conf to resolv against local unbound | 16:16 |
| clarkb | (it is using the correct servers accoprding to the unbound log, they aren't reachable though) | 16:16 |
| *** bdodd has joined #openstack-infra | 16:16 | |
| *** pgaxatte has quit IRC | 16:17 | |
| *** gfidente has quit IRC | 16:18 | |
| *** kopecmartin is now known as kopecmartin|off | 16:18 | |
| haleyb | it would be good to get a snapshot of what the system looks like right before this, like 'ip -6 a' and 'ip -6 r', etc, since i'm assuming we can't get in to look around when it fails? | 16:19 |
| clarkb | haleyb: we can that is what I'm trying to say. Worlddump is the tool we have for this | 16:23 |
| clarkb | its broken | 16:23 |
| clarkb | someone needs to fix it | 16:23 |
| *** e0ne has joined #openstack-infra | 16:23 | |
| clarkb | I'm working on a quick change to devstack to see if we can identify where it is broken | 16:24 |
| *** smarcet has quit IRC | 16:24 | |
| openstackgerrit | Merged opendev/base-jobs master: We need to set the build shard var in post playbook too https://review.opendev.org/680239 | 16:25 |
| openstackgerrit | Merged opendev/base-jobs master: Revert "Stop storing logs in OVH" https://review.opendev.org/680446 | 16:25 |
| *** yamamoto has joined #openstack-infra | 16:26 | |
| clarkb | haleyb: remote: https://review.opendev.org/680458 DO NOT MERGE debugging why worlddump logs are not collected | 16:27 |
| AJaeger | config-core, please review https://review.opendev.org/679856 and https://review.opendev.org/679652 | 16:27 |
| haleyb | clarkb: ack, i'll keep an eye on that, and look around some more | 16:27 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: Update to page titles and Users https://review.opendev.org/680459 | 16:31 |
| *** e0ne has quit IRC | 16:31 | |
| johnsom | clarkb After that restart it looks like our jobs aren't RETRY_LIMIT anymore. They seem to have made it to devstack. | 16:32 |
| *** chandankumar is now known as raukadah | 16:33 | |
| *** smarcet has joined #openstack-infra | 16:39 | |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: CSS fix for ul/li in FAQ https://review.opendev.org/680465 | 16:41 |
| openstackgerrit | Merged zuul/zuul-jobs master: Add build shard log path docs to upload-logs(-swift) https://review.opendev.org/680240 | 16:41 |
| *** zigo has quit IRC | 16:43 | |
| *** ramishra has quit IRC | 16:45 | |
| openstackgerrit | Merged openstack/project-config master: New charm for cinder integration with Purestorage https://review.opendev.org/679652 | 16:46 |
| clarkb | AJaeger: ^ there is one of them | 16:46 |
| AJaeger | thanks, clarkb | 16:48 |
| *** spsurya has quit IRC | 16:48 | |
| *** igordc has joined #openstack-infra | 16:49 | |
| zbr | clarkb: AJaeger any change to persuade you about emit-job-header improvement? https://review.opendev.org/#/c/677971/ | 16:49 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: CSS fix for ul/li in FAQ https://review.opendev.org/680465 | 16:49 |
| *** ullbeking has joined #openstack-infra | 16:50 | |
| *** jaosorior has quit IRC | 16:51 | |
| AJaeger | zbr: you add molecule files, I do not see where those are used - and I agree with pabelanger that this is in the inventory already... So, I'm torn whether this is really beneficial... | 16:54 |
| *** smarcet has quit IRC | 16:54 | |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: CSS fix for ul/li in FAQ https://review.opendev.org/680465 | 16:55 |
| zbr | AJaeger: molecule files enable a developer to do local testing (did not want to force you to use that tool). Re the comment, users already remarked that the inventory is not available until job finishes and also is not visible in console log. Do we worry about adding few bytes to the console? | 16:57 |
| zbr | arguably even the summary page does not include any information about ansible version used, or which python interpreter was used. | 16:58 |
| AJaeger | I'm missing the relevance, so will abstain here. Also, adding the molecule files is something we should discuss on #zuul. | 16:58 |
| clarkb | a few extra bytes is unlikely to be a problem when compared to the vast quantity of log output by jobs | 16:59 |
| zbr | yep, i am for reducing logs size, but starting where it matters. | 17:00 |
| AJaeger | mnaser: we merged the swift log changes that clarkb wrote, is your maintenance over and do you want us to use mtl1 again? your change https://review.opendev.org/678440 is still WIP | 17:00 |
| AJaeger | bbl | 17:00 |
| *** rosmaita has left #openstack-infra | 17:01 | |
| clarkb | AJaeger: note its only for the base-test so far and I'm testing that it works as we speak (waiting on test results) | 17:01 |
| zbr | regarding inclusion of test files, i am curious because we already do allow inclusion of stuff is is purely used for local testing, like `venv` section in tox.ini files, or some other sections which are run run on CI. | 17:01 |
| clarkb | AJaeger: mnaser but ya I'd love to push up a change that enables the build uuid sharding globally today and add vexxhost back to the mix if that is possible | 17:01 |
| clarkb | mnaser: ^ let us know | 17:01 |
| *** rh-jelabarre has quit IRC | 17:01 | |
| *** ociuhandu has joined #openstack-infra | 17:01 | |
| zbr | i am not trying to force anyone to adopt the tool, only reason why I included them was because I used them to test the change made to the role. | 17:02 |
| clarkb | zbr: I think the concern is that if we aren't testing it then we'll likely break it via changes made over time | 17:02 |
| zbr | and i do find them handy, but if that is a reason for not merging, i will remove them, is easy to recreate them, | 17:02 |
| *** markvoelker has quit IRC | 17:04 | |
| *** igordc has quit IRC | 17:04 | |
| fungi | zbr: we have historically used the testenv:venv definitions in some jobs, notably when producing release artifacts. at this stage they may be vestigial but i wouldn't wager a guess without additional research | 17:05 |
| *** tesseract has quit IRC | 17:06 | |
| zbr | sure. just put a comment with whatever i need to change, no hardfeelins, the only thing really useful was to print python path/version and ansible version (also could prove useful for logstash searches in the future). | 17:07 |
| *** jpena is now known as jpena|off | 17:07 | |
| *** zigo has joined #openstack-infra | 17:10 | |
| *** smarcet has joined #openstack-infra | 17:10 | |
| clarkb | infra-root: config-core: https://openstack.fortnebula.com:13808/v1/AUTH_e8fd161dc34c421a979a9e6421f823e9/zuul_opendev_logs_141/680178/1/check/tox-py27/1416af4/ the build uuid prefixing seems to work | 17:10 |
| *** markvoelker has joined #openstack-infra | 17:13 | |
| *** igordc has joined #openstack-infra | 17:15 | |
| openstackgerrit | Clark Boylan proposed opendev/base-jobs master: Shard build logs with build uuid in all base jobs https://review.opendev.org/680476 | 17:17 |
| clarkb | infra-root ^ that will take us to production | 17:17 |
| clarkb | and if mnaser gives us the go ahead we can enable vexxhost again once that is in? | 17:17 |
| *** udesale has quit IRC | 17:18 | |
| *** armax has quit IRC | 17:20 | |
| *** jaosorior has joined #openstack-infra | 17:21 | |
| *** larainema has quit IRC | 17:22 | |
| *** smarcet has quit IRC | 17:25 | |
| johnsom | clarkb Got one: https://zuul.openstack.org/build/8478f4bf656b412b8c613d19e10b1c25 | 17:25 |
| johnsom | https://www.irccloud.com/pastebin/5Mb14ZtR/ | 17:25 |
| *** igordc has quit IRC | 17:26 | |
| openstackgerrit | Clark Boylan proposed zuul/zuul-jobs master: Flip the order of the emit-job-header tests https://review.opendev.org/680477 | 17:28 |
| clarkb | johnsom: ya so something is breaking networking and that is ipv4 (not v6) | 17:29 |
| *** smarcet has joined #openstack-infra | 17:29 | |
| corvus | clarkb: did we delete all the logs_ containers in vexxhost? | 17:30 |
| clarkb | corvus: I believe mnaser did it for us | 17:30 |
| clarkb | because ceph was in a bad way | 17:30 |
| corvus | kk | 17:31 |
| johnsom | I still have that console open if you want me to look at the scrollback. At the surface it looks like ansible was happy before that. | 17:31 |
| clarkb | corvus: note: I have not double checked that and that would be a good cleanup (we'll want to clean all the logs_ containers in all the providers in ~30 days too) | 17:31 |
| corvus | clarkb: agree; let's just double check it then when we do that | 17:31 |
| clarkb | ++ | 17:32 |
| *** ociuhandu_ has joined #openstack-infra | 17:32 | |
| AJaeger | clarkb, corvus , change I5af7749fefec61f1e9fe8379266e799184a13807 added minimal retention only to base, but not base-minimal and base-test jobs - could you double check the 1month retention, please? See my comment at 680476... | 17:33 |
| openstackgerrit | Merged opendev/zone-opendev.org master: Increase mirror ttls to an hour https://review.opendev.org/680236 | 17:33 |
| clarkb | AJaeger: are you ok with that as a followup? | 17:33 |
| AJaeger | clarkb: it's unrelated to your change ;) I just noticed it when reviewing - so, followup is fine and your change is approved | 17:34 |
| openstackgerrit | Clark Boylan proposed opendev/base-jobs master: Set container object expiry to 30 days https://review.opendev.org/680480 | 17:34 |
| clarkb | AJaeger: ^ thank you for the reviews | 17:35 |
| AJaeger | great! thanks | 17:35 |
| *** ricolin has quit IRC | 17:35 | |
| *** ociuhandu has quit IRC | 17:36 | |
| *** ociuhandu_ has quit IRC | 17:36 | |
| clarkb | johnsom: looking at that it happens after tempest starts but fairly early | 17:36 |
| *** smarcet has quit IRC | 17:36 | |
| clarkb | johnsom: that almost implies to me it is either an import time issue (testr will import all the test files to find the tests) or something separate that happens to just line up with that timing wise | 17:36 |
| johnsom | Yeah, none of the tests completed. I had four other consoles open at the same time, they all went into the tests. | 17:37 |
| clarkb | johnsom: unfortunately worlddump won't help us when connectivity has gone away completely | 17:37 |
| clarkb | johnsom: we probably want to see if it is cloud or region specific as a next step | 17:40 |
| clarkb | johnsom: if it is then it could also be a provider problem | 17:41 |
| openstackgerrit | Merged opendev/base-jobs master: Shard build logs with build uuid in all base jobs https://review.opendev.org/680476 | 17:41 |
| johnsom | That ssh IP implies RAX IAD | 17:41 |
| *** smarcet has joined #openstack-infra | 17:48 | |
| clarkb | oh neat that change merged already | 17:50 |
| clarkb | exciting! | 17:50 |
| *** jamesmcarthur has quit IRC | 17:51 | |
| clarkb | mnaser: when you have a moment your feedback on whether or not these changes make you more comfortable running the log uploads against vexxhost again would be great | 17:51 |
| mnaser | clarkb: i guess the only thing that still feels like a bother is the sheer amount of ara-report's :( | 17:57 |
| clarkb | mnaser: I think corvus may be fiddling with options around taht? dmsimard is also brainstorming fixes here https://etherpad.openstack.org/p/Vz5IzxlWFz | 17:58 |
| clarkb | mnaser: did we see problems with the logs_XY containers in addition to the periodic container? | 17:58 |
| *** smarcet has quit IRC | 17:59 | |
| corvus | i expect to be able to propose a change that removes the top-level ara generation that happens to every job by the end of the week, if that's the way we want to go. it won't affect nested aras (eg, devstack). it's not clear to me what the balance between the two is (ie, of the X ara files, what percentage comes from the zuul run versus nested runs) | 18:00 |
| *** smarcet has joined #openstack-infra | 18:00 | |
| clarkb | note devastck doesn't do a nested ara I don't think | 18:01 |
| clarkb | but osa tripleo etc all do | 18:01 |
| *** rh-jelabarre has joined #openstack-infra | 18:01 | |
| *** jamesmcarthur has joined #openstack-infra | 18:04 | |
| *** armax has joined #openstack-infra | 18:04 | |
| *** mattw4 has quit IRC | 18:04 | |
| *** mattw4 has joined #openstack-infra | 18:05 | |
| *** smarcet has quit IRC | 18:06 | |
| *** smarcet has joined #openstack-infra | 18:07 | |
| *** jamesmcarthur has quit IRC | 18:07 | |
| *** diga has quit IRC | 18:10 | |
| *** smarcet has quit IRC | 18:16 | |
| clarkb | I've approved the gus2019 change for ssh idle timeout updates | 18:19 |
| clarkb | that should release the replication disabled on start change too | 18:20 |
| clarkb | once that gets applied to the gerrit server I'll work on doing some restarts (review-dev first) | 18:20 |
| *** jamesmcarthur has joined #openstack-infra | 18:23 | |
| paladox | you may also want to enable change.disablePrivateChanges when you upgrade gerrit. | 18:24 |
| clarkb | paladox: we effectively disabled them via preventing pushes to refs/for/draft or wahtever that meta ref is | 18:25 |
| clarkb | but I guess drafts went away and there is a new thing now? | 18:25 |
| paladox | this is a new thing | 18:25 |
| paladox | no longer uses refs. | 18:25 |
| paladox | users can create a open change and put it as private | 18:25 |
| paladox | like wip mode | 18:25 |
| clarkb | ah | 18:25 |
| * paladox enabled that at wikimedia | 18:25 | |
| paladox | as we wanted everything to be open | 18:26 |
| clarkb | ya also tends to create confusion when changes depend on a change that has since become private and so on | 18:26 |
| clarkb | however it may be useful for security bug fixes | 18:26 |
| paladox | yup | 18:26 |
| clarkb | we'll likely have to experiment with it | 18:26 |
| paladox | i've found that changes are not really hidden as the feature makes it out to be. | 18:27 |
| clarkb | ah | 18:27 |
| clarkb | in that case maybe not great for security bugs :) | 18:27 |
| paladox | I filed a bug about this some where upstream | 18:27 |
| paladox | https://bugs.chromium.org/p/gerrit/issues/detail?id=8111 | 18:28 |
| *** kjackal has quit IRC | 18:28 | |
| fungi | fwiw, that was one of the big problems about the old drafts feature as well, they claimed to be private but they were leaky | 18:30 |
| *** kjackal has joined #openstack-infra | 18:31 | |
| *** mriedem has quit IRC | 18:31 | |
| *** mriedem has joined #openstack-infra | 18:33 | |
| *** dtantsur is now known as dtantsur|afk | 18:36 | |
| clarkb | did we decide that https://opendev.org/openstack/project-config/src/branch/master/zuul.d/projects.yaml#L5263-L5267 is the cause of the openstack tenant config error because that repo doesn't have the zuul app on it? | 18:36 |
| *** igordc has joined #openstack-infra | 18:36 | |
| corvus | paladox: thanks -- added a note to https://etherpad.openstack.org/p/gerrit-upgrade | 18:37 |
| paladox | yw :) | 18:37 |
| corvus | clarkb: unsure; wanted to check with ianw upon his awakening | 18:38 |
| clarkb | k | 18:38 |
| paladox | corvus also native packaging is https://gerrit.googlesource.com/gerrit-installer/ :) | 18:40 |
| corvus | paladox: yeah, we're going to make our own image builds (mostly so that we have the option to fork if necessary, and can include exactly the plugins we use). that's working now, i think we just need to tweak some ownership/permissions stuff to match our current server in order to upgrade | 18:41 |
| *** mattw4 has quit IRC | 18:41 | |
| paladox | ah, ok :) | 18:41 |
| corvus | our dockerfile is heavily based on the gerritforce one :) | 18:41 |
| paladox | heh | 18:41 |
| corvus | gerritforge even | 18:41 |
| clarkb | I want to say the old step 0 plan was to switch to 2.13 via docker | 18:41 |
| clarkb | then upgrade via docker | 18:41 |
| corvus | clarkb: yeah, i think that's still good | 18:42 |
| paladox | corvus upgrading to NoteDB was cool! (dboritz added the notedb.config per my request as we use puppet at wikimedia) | 18:45 |
| *** pkopec has quit IRC | 18:47 | |
| paladox | All we did was set https://github.com/wikimedia/puppet/commit/06c8e4122c37508045d84840ac1cb23f4f7d9011#diff-4c58f684fb8a36946bc7616d35570c00 then after the upgrade https://github.com/wikimedia/puppet/commit/d0b08b9675438fe637374a165fdf28c375c3510a#diff-4c58f684fb8a36946bc7616d35570c00 | 18:49 |
| *** eernst has joined #openstack-infra | 18:51 | |
| openstackgerrit | Merged opendev/puppet-gerrit master: Set a default idle timeout for ssh connections https://review.opendev.org/678413 | 18:51 |
| paladox | ah, nice to see ^^ | 18:54 |
| paladox | we done similar https://github.com/wikimedia/puppet/commit/cf5c343cc787c46cce2d4d1f91b2ab0c09d3492f#diff-4c58f684fb8a36946bc7616d35570c00 | 18:54 |
| paladox | (task is hidden) | 18:54 |
| *** e0ne has joined #openstack-infra | 18:54 | |
| openstackgerrit | Merged opendev/puppet-gerrit master: Add support for replicateOnStartup config option https://review.opendev.org/678486 | 18:55 |
| openstackgerrit | Merged opendev/system-config master: Don't run replication on gerrit startup https://review.opendev.org/678487 | 18:55 |
| corvus | yeah, that was an amusing moment at the hackathon... most people couldn't understand how our server functioned at all without a timeout set, and we were like "theres a timeout option?" | 18:55 |
| *** eernst has quit IRC | 18:56 | |
| paladox | corvus it fixes other issues too :) | 18:56 |
| paladox | which i didn't realise at all could happen | 18:56 |
| clarkb | I'm pretty sure the timeout was set by default in older gerrit | 18:56 |
| clarkb | because I remember zuul losing its connection to our idle review-dev server | 18:56 |
| clarkb | I'll watch for those to apply to review-dev and restart it | 18:57 |
| *** eernst has joined #openstack-infra | 18:58 | |
| paladox | corvus you may also want to enable https://github.com/wikimedia/puppet/commit/0564af76c6067f58d5622c8f81ec36d3793f2ddd#diff-4c58f684fb8a36946bc7616d35570c00 (affects gerrit 2.16+) | 18:59 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: Removing erroneous og images https://review.opendev.org/680488 | 19:00 |
| *** eernst has quit IRC | 19:02 | |
| *** armstrong has quit IRC | 19:04 | |
| *** e0ne has quit IRC | 19:07 | |
| *** trident has quit IRC | 19:09 | |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: Replacing OG images with Zuul icon https://review.opendev.org/680490 | 19:10 |
| *** eernst has joined #openstack-infra | 19:10 | |
| *** e0ne has joined #openstack-infra | 19:12 | |
| *** e0ne has quit IRC | 19:14 | |
| *** eernst has quit IRC | 19:15 | |
| *** e0ne has joined #openstack-infra | 19:16 | |
| *** eernst has joined #openstack-infra | 19:17 | |
| *** e0ne_ has joined #openstack-infra | 19:18 | |
| *** trident has joined #openstack-infra | 19:20 | |
| *** e0ne has quit IRC | 19:21 | |
| *** eernst has quit IRC | 19:22 | |
| *** ralonsoh has quit IRC | 19:23 | |
| openstackgerrit | James E. Blair proposed zuul/zuul master: Web: rely on new attributes when determining task failure https://review.opendev.org/680498 | 19:34 |
| mriedem | is it normal to have a patch queued for nearly 20 hours right now? | 19:34 |
| mriedem | (679473,1) Handle VirtDriverNotReady in _cleanup_running_deleted_instances (19h18m/ | 19:34 |
| AJaeger | mriedem: not normal - we had a cloud failure and needed some restart, so that bit us ;( | 19:36 |
| AJaeger | mriedem: so, we have quite a backlog at the moment ;/ | 19:37 |
| corvus | the trend is heading in the right direction: \ | 19:37 |
| *** jamesmcarthur has quit IRC | 19:37 | |
| corvus | it was / then - now \ (ascii sparklines) | 19:37 |
| *** jamesmcarthur has joined #openstack-infra | 19:38 | |
| AJaeger | ;) | 19:38 |
| *** rosmaita has joined #openstack-infra | 19:42 | |
| *** jamesmcarthur has quit IRC | 19:42 | |
| *** eernst has joined #openstack-infra | 19:43 | |
| openstackgerrit | James E. Blair proposed opendev/base-jobs master: Remove ara from base-test https://review.opendev.org/680500 | 19:43 |
| openstackgerrit | James E. Blair proposed opendev/base-jobs master: Remove ara from base-test https://review.opendev.org/680501 | 19:43 |
| openstackgerrit | James E. Blair proposed opendev/base-jobs master: Remove ara from base https://review.opendev.org/680501 | 19:44 |
| corvus | clarkb, fungi, AJaeger, dmsimard: ^ that's an option i think we can consider now | 19:45 |
| corvus | mnaser: ^ | 19:45 |
| *** eernst has quit IRC | 19:46 | |
| *** eernst has joined #openstack-infra | 19:47 | |
| *** e0ne_ has quit IRC | 19:49 | |
| slittle1 | now we need additional cores to be added to the ten new repos created for starlingx yesterday | 19:52 |
| *** e0ne has joined #openstack-infra | 19:54 | |
| slittle1 | Can I add them directly myself? Or do I need to go through an admin ? | 19:55 |
| slittle1 | hmmm ... I'm not even on the core list. Guess I need an admin | 19:55 |
| clarkb | we add the first user then you add the rest | 19:55 |
| clarkb | give me a minute and I'll add you | 19:56 |
| slittle1 | ok, great | 19:56 |
| clarkb | just have to find the change again to get my list of repos | 19:57 |
| *** e0ne_ has joined #openstack-infra | 19:59 | |
| *** e0ne has quit IRC | 20:00 | |
| clarkb | slittle1: and done. You should be able to self manage the group membership now | 20:00 |
| slittle1 | great, thanks | 20:00 |
| *** eharney has quit IRC | 20:01 | |
| clarkb | I have restarted review-dev and it seemed to come up happy | 20:02 |
| clarkb | checking the replication log there are no entries in it for today | 20:02 |
| clarkb | I think that means the no replication on start flag is working | 20:03 |
| clarkb | I'm going to start a stream events ssh connection and see if it goes away in an hour | 20:03 |
| *** pkopec has joined #openstack-infra | 20:03 | |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: WIP: Support Ansible 2.9 https://review.opendev.org/674854 | 20:04 |
| AJaeger | corvus: Just checked the zuul UI for a job result - yes, I think we can drop ara | 20:04 |
| clarkb | no objections from me re dropping the root ara. We should send a note to the mailing list if we merge the production change though as people will notice | 20:07 |
| clarkb | but then maybe we can turn on vexxhost when mnaser is in a spot to keep an eye on his side of things and we monitor it? | 20:07 |
| paladox | clarkb note that changing replication.config when gerrit is running, effectively breaks replication until gerrit is restarted. (it's a known issue upstream, it bit us at wikimedia) | 20:08 |
| clarkb | paladox: we've not experienced that (we even have the replication config set to reload the plugin on updates) | 20:08 |
| clarkb | and we tested that and have made such changes multiple times | 20:08 |
| paladox | oh | 20:08 |
| *** jamesmcarthur has joined #openstack-infra | 20:09 | |
| clarkb | could be the older plugin version is fine? | 20:09 |
| paladox | it bit us, we didn't realise it was a bug until we investigated furthur. | 20:09 |
| paladox | possibly | 20:09 |
| clarkb | I plan on restarting production gerrit today too, though i do need to pop out for a bit now then do phone calls | 20:09 |
| clarkb | wanting to verify the sshd idleTimeout first though | 20:10 |
| fungi | clarkb: i thought what we observed was that if the replication config is modified while gerrit is running, it discards all pending replication events in its queue | 20:13 |
| fungi | and so we noted that maybe we should just disable that "feature" instead | 20:14 |
| fungi | (but i don't recall whether we got around to actually disabling it) | 20:14 |
| openstackgerrit | Merged opendev/base-jobs master: Remove ara from base-test https://review.opendev.org/680500 | 20:16 |
| clarkb | oh ya that may be | 20:16 |
| *** e0ne_ has quit IRC | 20:19 | |
| paladox | fungi that's been fixed i think unless it was reverted. | 20:26 |
| fungi | well, odds are it wasn't fixed back in 2.13 (or we missed picking up a relevant backport) | 20:29 |
| paladox | fungi https://bugs.chromium.org/p/gerrit/issues/detail?id=10260 | 20:32 |
| *** lpetrut has joined #openstack-infra | 20:34 | |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: Switch ansible_default to 2.8 https://review.opendev.org/676695 | 20:38 |
| openstackgerrit | Paul Belanger proposed zuul/zuul master: WIP: Support Ansible 2.9 https://review.opendev.org/674854 | 20:38 |
| *** lpetrut has quit IRC | 20:38 | |
| *** ociuhandu has joined #openstack-infra | 20:39 | |
| *** Goneri has quit IRC | 20:44 | |
| *** ociuhandu has quit IRC | 20:45 | |
| *** ociuhandu has joined #openstack-infra | 20:46 | |
| *** jamesmcarthur has quit IRC | 20:48 | |
| *** iurygregory has quit IRC | 20:50 | |
| *** ociuhandu has quit IRC | 20:50 | |
| *** jamesmcarthur has joined #openstack-infra | 20:50 | |
| clarkb | corvus: what is the next step for https://review.opendev.org/#/c/680501/ do we have a test chagne for that yet? I guess you can use https://review.opendev.org/#/c/680178/ which I have just rechecekd. | 20:58 |
| clarkb | about now is when I expected review-dev to kill my ssh connection | 21:02 |
| clarkb | it hasn't happened yet. | 21:03 |
| clarkb | oh it just happend \o/ | 21:03 |
| clarkb | ok those two changes are confirmed to be working on review-dev I think | 21:03 |
| clarkb | next step is restarting gerrit on review.o.o | 21:03 |
| clarkb | are any other roots around? should I just go for it? | 21:04 |
| clarkb | hrm there is one change in the release pipeline I'll go let the release team know | 21:04 |
| *** markvoelker has quit IRC | 21:05 | |
| *** diablo_rojo has quit IRC | 21:06 | |
| *** diablo_rojo has joined #openstack-infra | 21:07 | |
| clarkb | fungi: are you around enough to be a second set of hands/eyeballs if needed for gerrit restart? | 21:08 |
| *** rh-jelabarre has quit IRC | 21:08 | |
| fungi | clarkb: sure, i've just finished up post-election tasks (i hope) | 21:09 |
| clarkb | fungi: maybe you can wrote up a status notice? and I'll login and double check configs are in place on that server and proceed with restarting it | 21:09 |
| *** mattw4 has joined #openstack-infra | 21:10 | |
| clarkb | configs are in place I'm ready to stop gerrit and start it when you are | 21:10 |
| *** markvoelker has joined #openstack-infra | 21:11 | |
| clarkb | how about #status notice Gerrit is being restarted to pick up configuration changes. Should be quick. Sorry for the interruption. | 21:11 |
| fungi | that wfm, i had one half-typed | 21:11 |
| fungi | but slow going as i'm not at my usual keyboard | 21:12 |
| clarkb | I'll start asking systemd to do that nicely if you want to send the notice | 21:12 |
| fungi | #status notice Gerrit is being restarted to pick up configuration changes. Should be quick. Sorry for the interruption. | 21:12 |
| openstackstatus | fungi: sending notice | 21:12 |
| -openstackstatus- NOTICE: Gerrit is being restarted to pick up configuration changes. Should be quick. Sorry for the interruption. | 21:14 | |
| clarkb | the log file and systemd think it is running | 21:14 |
| *** markvoelker has quit IRC | 21:15 | |
| clarkb | and gerrit queue is largely empty | 21:15 |
| clarkb | (so replicationi config appears to ahve worked here too) | 21:15 |
| openstackstatus | fungi: finished sending notice | 21:16 |
| clarkb | web ui is up and running for me | 21:16 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: OK, trying again to update with the correct og image tags, removing the erroneous gitlab tags. https://review.opendev.org/680520 | 21:16 |
| fungi | working for me | 21:16 |
| clarkb | seems like people can push to it too ^ :) | 21:17 |
| *** pkopec has quit IRC | 21:17 | |
| fungi | indeed! | 21:17 |
| clarkb | context switching: the ara removal seems to haev worked fine. https://33989e35e43da1db0b96-a619ea89024f9935a8230ca8f397a8a1.ssl.cf2.rackcdn.com/680178/1/check/tox-py35/e5c7f47/ maybe want to double check the dashboard renders that once sql reporting happens | 21:17 |
| clarkb | https://storage.bhs1.cloud.ovh.net/v1/AUTH_dcaab5e32b234d56b626f72581e3644c/zuul_opendev_logs_f83/680178/1/check/tox-py27/f839885/ as well | 21:17 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: OK, trying again to update with the correct og image tags, removing the erroneous gitlab tags. https://review.opendev.org/680520 | 21:19 |
| openstackgerrit | Jimmy McArthur proposed zuul/zuul-website master: OK, trying again to update with the correct og image tags, removing the erroneous gitlab tags. https://review.opendev.org/680520 | 21:20 |
| clarkb | corvus: I +2'd https://review.opendev.org/#/c/680501/2 as well as AJaeger and fungi so I think that can happen as soon as we like | 21:20 |
| clarkb | I can also send email about it to the mailing lists if you would prefer I did that | 21:20 |
| clarkb | (but will wait for the chagne to be approved before doing that) | 21:20 |
| *** bdodd_ has joined #openstack-infra | 21:26 | |
| *** bdodd has quit IRC | 21:27 | |
| clarkb | fungi: https://review.opendev.org/#/c/680480/ makes base-test and base-minimal match base on their object expiry dates. https://review.opendev.org/#/c/680477/ is a simple order change to make the last emit-job-header url match what will actually be uploaded to | 21:28 |
| clarkb | those are the last two things I had related to swift and corvus' ara change is the other thing | 21:28 |
| clarkb | looks like corvus just removed his WIP on that change. | 21:29 |
| *** jamesmcarthur has quit IRC | 21:29 | |
| corvus | yep -- though i guess you were thinking of waiting until 680178 reports | 21:30 |
| clarkb | ya though I guess I'm not super concerned about that since we can confirm the dashboard works with ara in place too | 21:31 |
| clarkb | at first I was thinkign we needed the sql report to confirm that then realized we don't | 21:31 |
| clarkb | since all jobs with or without ara get that dashboard stuff | 21:31 |
| corvus | yeah, i think the thing to check would be if there's something weird about the file layout without the generated report | 21:32 |
| corvus | it's more of an unknown unknown thing :) | 21:32 |
| clarkb | k happy to wait for that then | 21:32 |
| *** jcoufal has quit IRC | 21:32 | |
| *** jamesmcarthur has joined #openstack-infra | 21:50 | |
| openstackgerrit | Merged opendev/base-jobs master: Set container object expiry to 30 days https://review.opendev.org/680480 | 21:53 |
| *** jamesmcarthur has quit IRC | 21:55 | |
| *** slaweq has quit IRC | 22:03 | |
| openstackgerrit | Merged opendev/base-jobs master: Remove ara from base https://review.opendev.org/680501 | 22:06 |
| *** claudiub has joined #openstack-infra | 22:07 | |
| *** AJaeger_ has joined #openstack-infra | 22:10 | |
| *** kjackal has quit IRC | 22:10 | |
| *** slaweq has joined #openstack-infra | 22:11 | |
| *** AJaeger has quit IRC | 22:14 | |
| *** jamesmcarthur has joined #openstack-infra | 22:16 | |
| ianw | clarkb: re zuul errors for testinfra @ https://opendev.org/openstack/project-config/src/branch/master/zuul.d/projects.yaml#L5263-L5267 | 22:17 |
| ianw | the project does have the zuul app on it -- but i don't think it did have the app when zuul actually started | 22:18 |
| clarkb | ah so if we trigger a full reconfigure that may go away? | 22:18 |
| ianw | maybe? | 22:18 |
| clarkb | corvus: on 680178 zuul has decided it needs to run all the tests against that change now? | 22:19 |
| clarkb | odd | 22:19 |
| pabelanger | ianw: clarkb: IIRC, you might need to stop / start zuul, in that case. I've seen that with github, but cannot remember the fix ATM | 22:20 |
| pabelanger | for now, I always try to make sure github app is installed before adding it to zuul tenant config | 22:20 |
| *** jamesmcarthur has quit IRC | 22:21 | |
| *** slaweq has quit IRC | 22:21 | |
| corvus | we should try a full reconfiguration. if that does not fix the problem it's a bug. | 22:21 |
| corvus | a restart should *never* be necessary. | 22:21 |
| openstackgerrit | Clark Boylan proposed zuul/zuul-website master: Add Zuul FAQ page https://review.opendev.org/679670 | 22:22 |
| pabelanger | ianw: have you started working on adding fedora-30 to nodepool-builders? or does that need dib release | 22:22 |
| ianw | pabelanger: i just need to update for that gate missing you mentioned, then i think we can dib release | 22:22 |
| openstackgerrit | Clark Boylan proposed zuul/zuul-website master: CSS fix for ul/li in FAQ https://review.opendev.org/680465 | 22:23 |
| pabelanger | ianw: great! will hold off on testing until then | 22:23 |
| *** eernst has quit IRC | 22:23 | |
| *** jamesmcarthur has joined #openstack-infra | 22:25 | |
| *** prometheanfire has quit IRC | 22:25 | |
| *** prometheanfire has joined #openstack-infra | 22:26 | |
| corvus | clarkb: yep, that's pretty weird, it shouldn't be doing that. | 22:26 |
| openstackgerrit | Ian Wienand proposed openstack/diskimage-builder master: Add fedora-30 testing to gate https://review.opendev.org/680531 | 22:26 |
| corvus | most of those jobs don't inherit from unittests | 22:26 |
| ianw | clarkb / corvus: there does however seem to be something wrong with running the system-config job against upstream testinfra ... https://zuul.opendev.org/t/openstack/build/a018575d4d4e4710b763978069c9cf12/log/job-output.txt#3559 | 22:28 |
| ianw | "Cloning into '/opt/system-config'...\nfatal: '/home/zuul/src/opendev.org/opendev/system-config' does not appear to be a git repository\ | 22:28 |
| ianw | it doesn't run that often, but i think it's failed like that every time | 22:28 |
| clarkb | ianw: you may need to add that repo as a required project on the job | 22:28 |
| ianw | huh ... yeah, i didn't think of that ... different project | 22:29 |
| *** jamesmcarthur has quit IRC | 22:30 | |
| corvus | yeah, if you look here you can see the command: https://zuul.opendev.org/t/openstack/build/a018575d4d4e4710b763978069c9cf12/console#2/1/2/bridge.openstack.org | 22:30 |
| corvus | it's what clarkb said | 22:30 |
| ianw | haha, sorry yeah seems obvious now. here i am thinking that the base jobs have some missing matching or something crazy | 22:31 |
| openstackgerrit | Ian Wienand proposed openstack/project-config master: testinfra : add system-config as required project https://review.opendev.org/680534 | 22:36 |
| *** kaisers has quit IRC | 22:37 | |
| openstackgerrit | Merged zuul/zuul-jobs master: Flip the order of the emit-job-header tests https://review.opendev.org/680477 | 22:37 |
| *** kaisers has joined #openstack-infra | 22:38 | |
| *** eernst has joined #openstack-infra | 22:43 | |
| *** eernst has quit IRC | 22:44 | |
| openstackgerrit | Ian Wienand proposed openstack/project-config master: testinfra : add system-config as required project https://review.opendev.org/680534 | 22:44 |
| ianw | ... duur not openstack/system-config ... get with the times :) | 22:45 |
| *** eernst has joined #openstack-infra | 22:46 | |
| *** igordc has quit IRC | 22:48 | |
| *** mriedem has quit IRC | 22:50 | |
| *** eernst has quit IRC | 22:51 | |
| ianw | corvus / clarkb : so was the conclusion i should SIGHUP zuul? | 22:52 |
| clarkb | ianw: or run the zuul-scheduler command that reconfigures it ( Ithink it is a zuul-scheduler command) | 22:53 |
| clarkb | either way should work | 22:53 |
| corvus | zuul-scheduler full-reconfigure | 22:53 |
| corvus | that's the future, but sighup should still work for now i think | 22:53 |
| *** exsdev has quit IRC | 22:54 | |
| ianw | ok, just ran full-reconfigure | 22:54 |
| *** exsdev has joined #openstack-infra | 22:54 | |
| fungi | https://zuul-ci.org/docs/zuul/admin/components.html#operation | 22:55 |
| fungi | for reference | 22:55 |
| corvus | it'll take a while -- it's done when the timestamp on the bottom of the status page updates | 22:55 |
| clarkb | https://etherpad.openstack.org/p/ara-removed-from-jobs how does that llok for giving people notice of the ara change | 22:56 |
| corvus | clarkb: seems good | 22:57 |
| fungi | looks fine to me | 22:58 |
| clarkb | I'll send that to the zuul airship and starlingx ml too | 23:01 |
| clarkb | (but will send separate emails) | 23:01 |
| ianw | so last reconfigured -> Fri Sep 06 2019 08:59:51 GMT+1000 (Australian Eastern Standard Time) | 23:02 |
| *** tkajinam has joined #openstack-infra | 23:02 | |
| ianw | (that was 2 minutes ago) | 23:02 |
| corvus | ianw: so still no joy there. if a restart fixes it, we have a bug in zuul; if it doesn't, then something something github | 23:03 |
| corvus | it is, however, not a good time for a restart | 23:03 |
| ianw | yeah, just wait for something else to come up i guess. but it does report (despite the job dependency issue) ... so it is talking to github clearly | 23:04 |
| clarkb | https://zuul.opendev.org/t/zuul/build/f83988533a4847b4ad6e7e1948755938/logs has no ara-report https://zuul.opendev.org/t/zuul/build/f83988533a4847b4ad6e7e1948755938/console is happy | 23:08 |
| clarkb | I'll send the email now | 23:08 |
| *** slaweq has joined #openstack-infra | 23:11 | |
| clarkb | mnaser: to catch up the major changes we've made are to: use a opendev specific container name prefix so that multiple zuul installs can run against a single ceph install (address global container namespace), suffixed container names with first three characters of build uuid sharing all builds into 4096 containers, and removed the top level zuul ara report | 23:15 |
| clarkb | some jobs will still run ara internally and we havne't changed those, but we did stop creating a report for every job | 23:16 |
| *** slaweq has quit IRC | 23:16 | |
| openstackgerrit | Merged openstack/project-config master: testinfra : add system-config as required project https://review.opendev.org/680534 | 23:21 |
| *** rcernin has joined #openstack-infra | 23:23 | |
| *** threestrands has joined #openstack-infra | 23:30 | |
| ianw | can we trigger rechecks via github comments? | 23:33 |
| clarkb | yes "recheck" should work just lik ewith gerrit | 23:34 |
| ianw | hrm doesn't for testinfra, but perhaps that is related to the config error. maybe new events work but not update checks? | 23:36 |
| aspiers | Is it possible to configure zuul to fail early if certain jobs fail? The docs suggest that pipeline.failure can do it | 23:37 |
| aspiers | but as you can tell I haven't a clue about zuul config yet ... | 23:37 |
| ianw | aspiers: this comes up a bit, you can setup dependencies ... | 23:42 |
| *** dchen has joined #openstack-infra | 23:42 | |
| aspiers | I mean, e.g. if the pep8 job fails, then immediately cancel a 2 hour tempest job | 23:43 |
| aspiers | that kind of thing | 23:43 |
| aspiers | so that CI resources aren't wasted on broken changes | 23:43 |
| aspiers | although it would have to be cleverer than that | 23:43 |
| clarkb | we actually did try this a long time ago | 23:43 |
| clarkb | the problme is then you end up pushing many patchstes as you work through multiple failures | 23:44 |
| clarkb | rather than getting as complete a picture as possible upfront | 23:44 |
| aspiers | yes, I think there's a trade-off to be had somewhere | 23:44 |
| clarkb | but zuul does still support that fail fast iirc | 23:44 |
| clarkb | (we never removed the functionality just stopped using it) | 23:44 |
| aspiers | e.g. in nova, always run all the shorter running unit/functional test suites, but if any of those fail, then cancel the really slow and expensive tempest / grenade jobs | 23:45 |
| aspiers | I get the impression that 90% of nova failures are caught by the unit/functional tests | 23:45 |
| aspiers | ICBW | 23:45 |
| clarkb | oh ya for that you have to set up the dependencies | 23:45 |
| aspiers | the problem with not cancelling is that the queue gets really backlogged, like it is right now (hence my asking) | 23:46 |
| aspiers | For example 680296,1 has already failed openstack-tox-pep8 but some other jobs have been running for ALMOST 19 HOURS(!), taking up valuable CI resources | 23:46 |
| clarkb | they have been in the queue for that long not running for that long | 23:47 |
| aspiers | oh OK | 23:47 |
| aspiers | but still | 23:47 |
| aspiers | anything waiting in the queue that long is not good | 23:47 |
| aspiers | https://www.klipfolio.com/blog/cycle-time-software-development | 23:47 |
| clarkb | yes but the problem is due to external factors which have been corrected and we are now waiting to catch back up again | 23:48 |
| aspiers | actually https://codeclimate.com/blog/software-engineering-cycle-time/ is a better read | 23:48 |
| aspiers | ohhhh OK | 23:48 |
| aspiers | now you mention it, I did vaguely notice an IRC announcement about Gerrit earlier | 23:48 |
| clarkb | but also gate failures have significantly larger impacts on queue times because of the cost of gate resets | 23:48 |
| aspiers | brain too fried to make the connection ;-) | 23:48 |
| clarkb | this is why EVERY time this topic comes up I point people to elastic-recheck | 23:49 |
| clarkb | and ask people to focus on fixing the bugs in our software | 23:49 |
| clarkb | as step 0 | 23:49 |
| aspiers | yeah :) | 23:49 |
| clarkb | because then we win with better software and shorter queues | 23:49 |
| clarkb | instead of just shorter queues with just as broken software | 23:49 |
| aspiers | I was assuming the backlog was due to nova being in the last week before feature freeze, hence a flurry of reviews | 23:49 |
| aspiers | Thanks a lot for all the info. As usual this channel is like 19 steps ahead of my thoughts ;-) | 23:51 |
| aspiers | Back to writing my first ever tempest tests \o/ | 23:51 |
| *** rcernin is now known as rcernin|brb | 23:52 | |
| clarkb | aspiers: the other way to make a large impact is to reduce job runtimes (which is the other thing I' vebrought up recently with devstack runtimes and OOMing jobs) | 23:53 |
| clarkb | they get really slow due to lack of memory | 23:53 |
| aspiers | makes sense | 23:53 |
| *** jamesmcarthur has joined #openstack-infra | 23:58 | |
Generated by irclog2html.py 2.15.3 by Marius Gedminas - find it at mg.pov.lt!
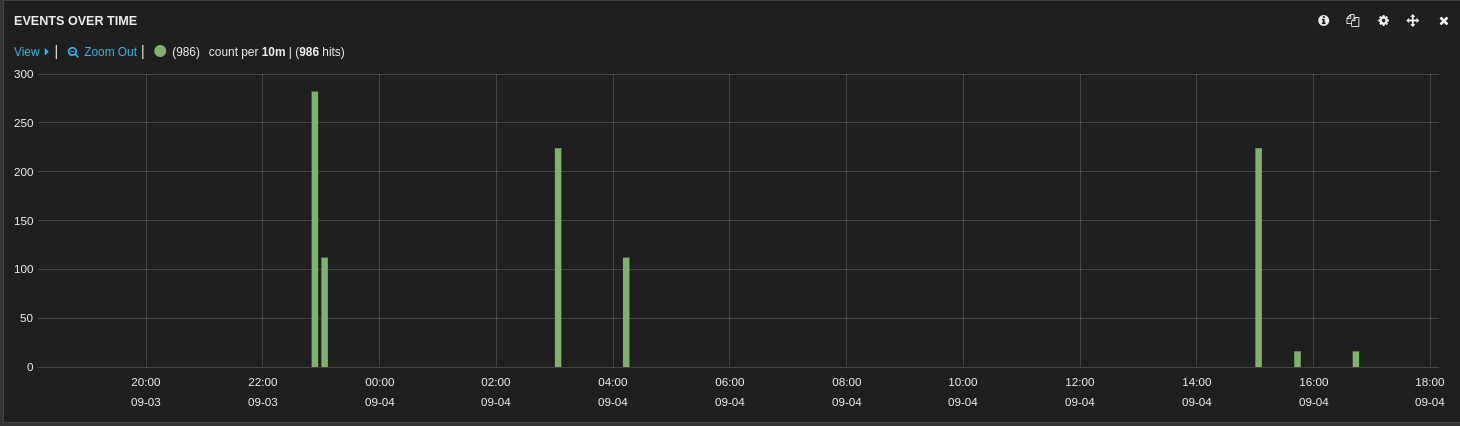{kind=link}